
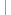
Beiträge
Themengruppen
Recherche
Service
- Was ist Wissensmangement?
- Open Journal of Knowledge Management
- Artikel-Guidelines
- Newsletter
- Kalender
- Wissensmanagement-Anbieter
- Partner
- Mediadaten
Community
Sponsoren

- Erstellung einer Datenbasis, wie in Abb. 2
- Data Cleaning, i.e. Entfernung von rauschenden und inkonsistenten Daten
- Data Integration, i.e. die Einbettung von Material aus unterschiedlichen Quellen wie in Abb.2
- Data Selection, i.e. die für die Aufgabe relevanten Daten werden aus der Database geholt
- Data Transformation & Reduction, i.e. das Material wird z. B. aggregiert (Beispiele dafür s. u.)
- Data Mining, i.e. intelligente (=induktive) Algorithmen graben nach Mustern und Regeln
- Pattern Evaluation & Knowledge Presentation, i.e. Trennung von interesting und uninteresting Patterns + Präsentation
Knowledge Discovery in Databases, Teil I - Methodik und Anwendungsbereiche
27. November 2002 von Gebhard DettmarMit einer wachsenden Bereitschaft, Informationen als wirtschaftlichen Produktionsfaktoren eine gegenüber herkömmlichen Größen wie Rohstoff, Kapital und Arbeit zunehmende Bedeutung beizumessen, steigt das Bedürfnis nach einer adäquaten, zielgerichteten Informationsauswertung und -aufbereitung mehrwertbehafteten Datenmaterials. Um aus ungeordneten, ja unüberschaubaren Datenmengen Informationen zu extrahieren, bedarf es einer eigenen Methodologie sowie technischer Umsetzungsgrundlagen, die nicht von ungefähr ihre Umsetzung hauptsächlich im eCommerce und eBusiness finden. Im folgenden sollen Einsatzbereiche der Knowledge Discovery in Databases (KDD) vorgestellt und vor allem in die grundlegenden methodischen Ansätze eingeführt werden.
Einführung KDD
Im eCommerce und eBusiness machte man, schneller als manchen Beteiligten lieb sein konnte, die Erfahrung, dass steigender Web-Traffic nicht automatisch wachsende Käuferzahlen nach sich zieht. Erfolgsentscheidend auf diesem Gebiet sind vielmehr zuverlässige Konzepte zur Kundenbindung. Man geht derzeit von einem durchschnittlichen Kostenaufwand zwischen 150 - 300 Dollar pro gewonnenem Neukunden im eCommerce aus [1] . Es ist also aus ökonomischer Sicht zwingend erforderlich, dass ein überwiegender Teil eines so aufwändig rekrutierten Kreises auch Wiederholungskäufe tätigt. Diese Konzepte zu entwickeln ist das primäre Aufgabenfeld des electronic Customer Relationship Managements (i. f. eCRM), das eine datengetriebene Informationsgewinnung über die Personen zum Inhalt hat, die man seinem Kundenstamm anzufügen beabsichtigt. Es klingt bereits an, dass hier Selektion im Spiel ist: bevor man Datenmaterial mit dem Ziel der Informationsgewinnung für eine beabsichtigte Kundenbindung erhebt, muss man wissen, wen man binden möchte - und wen nicht.
Die Strategie der Kundensegmentierung hat also zwei wesentliche Bereiche abzudecken: die Risikoanalyse und das Auffinden geeigneter Marketingaktivitäten. Beides gibt es nicht erst seit dem Durchbruch des eCommerce: Im Bankenwesen, hauptsächlich in den Sektoren Retailbanking und Kreditkartenwesen, werden seit Beginn der 70er Jahre Methoden eingesetzt, die dem Bereich des Data Mining entstammen. Neben der Risikoanalyse vor einer eventuellen Kreditvergabe ist es weiterhin die Aufdeckung gut verkäuflicher Produktkombinationen, die seit geraumer Zeit mit Data Mining-Methoden bestritten wurde und wird. Die Problemstellungen des eCommerce brachten jedoch eine beträchtliche Erweiterung nicht nur der Zusammensetzung einer Datenbasis, auf die noch näher einzugehen sein wird, sondern auch des methodologischen Spektrums mit sich, zudem einen Reifegrad der technischen Umsetzung, der Nutzbarkeit in einem schier unbegrenzten Feld verspricht: Einzelhandel, Telekommunikation, Versicherungen, Kommunen, Sozialsysteme und Gesundheitswesen, alle bedienen sich eines Instrumentariums, das seinen Ursprung im Data Mining hat.
Dieser Artikel behandelt einen nicht nur im eCommerce verwendeten methodischen Ansatz, der mit Data Mining auf einer Ebene steht, i. e. Knowledge Discovery in Databases (KDD). Dabei sollen die einzelnen Schritte eines solchen Prozesses unter verschiedenen strategischen Vorgehensweisen vorgestellt und nachvollziehbar veranschaulicht werden, um dem Leser etwas von dem Hintergrundwissen und der Intuition zu vermitteln, über die im Data Mining der Analyst verfügen muss. Mit diesen Voraussetzungen kann er dann im 2. Teil einen Praxisbericht aus dem Bereich des Web Mining mitverfolgen, der Projektstatus hat und dessen Ergebnisse offen sind. Das Forum auf der Startseite wird ihm die Möglichkeit bieten, sich einzubringen und Einfluß zu nehmen, gegebenenfalls wird auch eine Mailingliste eingerichtet.
Knowledge Discovery in Databases und Data Mining
Ein Definitionsbegriff von Data Mining, der sich durchgesetzt zu haben scheint, wurde 1997 von Berry und Linoff so formuliert: "the process of exploration and analysis, by automatic or semi-automatic means, of large quantities of data in order to discover meaningful patterns and results." [2] Demgegenüber definierten Fayyad u.a. KDD als: "the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data." Die Semantik beider Definitionen ist nahezu synonym und tatsächlich werden beide Begriffe häufig austauschbar gebraucht.
In Publikationen, in denen Wert auf Begriffsschärfe gelegt wird, ist dagegen häufig die Neigung anzutreffen, Data Mining unter dem Oberbegriff Business Intelligence zu fassen, wo es ein verfahrenstechnisches Procedere oftmals auf Basis von Data Warehouses leistet, während KDD die Ansätze der künstlichen Intelligenz (AI) zugeschrieben werden, die selbstverständlich in Wirklichkeit einem erweiterten Data Mining Begriff ebenso zugrunde liegen.
In Data Warehouse-Umgebungen - der Begriff verrät bereits, dass es sich hier im wesentlichen um eine bestimmte Architektur handelt, sc. eine von den operationalen DV-Systemen und anderen externen Datenquellen entkoppelte Datenbank - wird aus diesen Quellen gewonnenes Material nach einer Aufbereitungs- und Entkoppelungsphase in aggregierter Form in sog. Data Marts der weiteren Verarbeitung zur Verfügung gestellt. Es ist möglich, aber nicht unproblematisch [3] , diese Weiterverarbeitung auch in einem Data Mining-Prozeß erfolgen zu lassen. Schematisch sieht der Vorgang so aus:
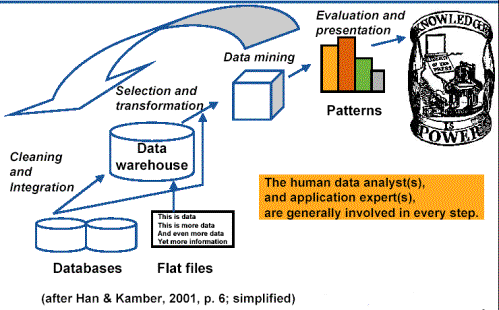
Abb. 1, entn. aus: Bettina Berendt, Web Mining Seminar III: Data mining techniques and resources, S. 8
Der Gesamtprozess KDD unterteilt sich also in die Schritte:
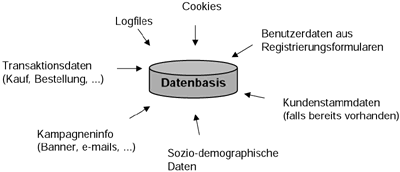
Abb. 2, entn. aus Hippner, Merzenich, Wilde (2002), S. 15
|
Üblicherweise betrachtet man KDD also als Überbegriff zu Data Mining. In einer solchen Konzeption zielt letzterer Begriff dann auf die Phase des maschinellen Lernens im KDD-Prozeß. Jedenfalls ist beiden Verfahren wesentlich zu eigen, dass sie sich höherer Analyseverfahren der künstlichen Intelligenz, wie z. B. neuronaler Netze oder Entscheidungsbäume bedienen, die - das ist der entscheidende Punkt - der Aufdeckung bisher unbekannter Sachverhalte dienen sollen. Datenbankabfragen z. B. beruhen auf Vorannahmen des Analysten, ja sind prinzipiell nichts anderes als in einer bestimmten Syntax formulierte Annahmen und Erwartungen. Bisher unbekannte Sachverhalte können so nicht aufgedeckt werden, zudem lassen sich Vorannahmen nicht automatisieren. Automatisierung aber ist das eigentliche Betätigungsfeld in der AI und deshalb sind alle Analyseverfahren, die auf Hypothesen beruhen, hier verpönt. Data Mining bedient sich aber auch herkömmlicher statistischer Verfahren, wie z. B. Clustering oder erhält, v.a. wenn es in Data Warehouses eingesetzt wird, durch SQL-Abfragen vorgefiltertes oder durch OLAP-Techniken aggregiertes, d.h. aus Sicht der AI-Forschung unter Vorgabe von Hypothesen manipuliertes Datenmaterial. Puristen lehnen ein solches Vorgehen strikt ab, es ist jedoch schon aus epistemologischer Sicht außerordentlich fraglich, ob man auch auf Seiten des maschinellen Lernens ohne Vorannahmen auskommt. Wir werden im Fortlauf sehen, dass das nicht der Fall ist.
Data Mining als Prozess im Maschinellen Lernen
Der Prozess des Maschinellen Lernens besteht prinzipiell in einer schrittweisen Reduktion der Fehleranfälligkeit, d.h., jede nachfolgende Aufgabe wird genauer gelöst als die vorausgehende. Man unterscheidet hierbei zwischen induktivem und deduktivem Lernen. Letzteres setzt auf bereits vorhandene, aus Datenbeständen extrahierte Wissensbasen auf, analysiert diese, um das enthaltene Wissen effizient und v.a. automatisiert einsetzen zu können. Deduktion bezeichnet bekanntlich einen Ableitungsprozess nach bestimmten Regeln, die Expertenwissen voraussetzen. Demgemäß sind Datenbestände hier eher klein, Wissensbasen dagegen groß. Damit scheidet es für Data Mining aus, Anwendungsgebiete sind v.a. technische Regelungsprozesse, sei es in der Steuerung von Stahlöfen oder Straßenbahnen oder der von Haushaltsgeräten. Induktives Lernen dagegen spiegelt in methodischer Hinsicht exakt die Eigenschaften eines Data Mining-Prozesses wieder, sc. große und sehr große Datenmengen bei nicht oder kaum vorhandenem Wissen über sie. Induktion bedeutet, vom besonderen auf das Allgemeine zu schließen, d.h. man extrahiert aus einer Datenbasis (=das besondere) Informationen, die man anschließend in eine Modellform (= allgemein) kleidet, indem man ähnlichen Daten Objektcharakter zuweist und dann in Klassen (z.B. kreditwürdig, riskant, nicht kreditwürdig) gruppiert. Im folgenden soll dann die Klassenzuordnung neu auftretetender Objekte vorausbestimmt werden können. Diesen Vorgang nennt man überwachtes Lernen, insgesamt gliedert sich der Data-Mining Prozess im Kontext des maschinellen Lernens wie folgt (Krahl, Windheuser, Zick (1998), S. 61)
Abb. 3, entn. aus Krahl, Windheuser, Zick (1998), S. 61
Der wesentliche Unterschied zwischen überwachtem und unüberwachtem Lernen besteht darin, dass in letzterem sowohl interessante (interesting patterns) als auch vorher nicht erwarte Strukturen (unexpected patterns) aufzudecken sind. Deshalb können hier nicht, wie im überwachten Lernen, Klasseneinteilungen vorgegeben werden, vielmehr sind Ähnlichkeiten zwischen Objekten und daraus resultierende Klassifikationen vom System selbständig aufzufinden und vorzuschlagen. Ansonsten können die Verfahren aus beiden Bereichen starke Ähnlichkeiten aufweisen, wie es z.B. zwischen k-nearest-Neighbour und k-means-Clustering der Fall ist.
Clustering-Algorithmen: k-means / k-nearest neighbour
In beiden Fällen ist k eine positive ganze Zahl, k ≥ 1, der entsprechend dem zu klassifizierenden Objekt k nächstähnliche Objekte zugeordnet werden, über die im ersteren Fall das Objekt spezifiert wird. Beim k-means-Clustering muss jedoch diese Zahl erst durch Trainingsläufe ermittelt werden. Dazu benötigt man eine bestimmte Menge von Datensätzen, die Zahl k>1 sowie eine Abstandsfunktion (entweder mathematisch, z. B. der euklidische Abstand für Punkte auf einer Ebene, oder nach Problemstellung im Praxisfall, z. B. Entfernung zwischen Städten [4] ), um ähnliche Datensätze zusammenfassen zu können. Aus den n Datensätzen werden nun k zufällig gezogen und als Repräsentanten festgelegt. Der verbleibende Rest, also n-k, wird mit diesen ausgewählten über die Abstandsfunktion verglichen und entsprechend zugeordnet. Daraufhin errechnet man von jedem entstandenen Cluster den Durchschnitt (=means) und verfährt solange weiter wie oben, bis sich in den Clustern keine Änderungen, bzw. sich keine neuen Cluster mehr ergeben. Ein Anwendungsbeispiel für k-nearest neighbours bilden alle Portale mit Community-Charakter, die ihren Kunden Produktratings und div. andere Interaktionsformen zur Verfügung stellen. Diese werden ja bekanntlich auch zu Kaufempfehlungen herangezogen. Hat nun ein Kunde zu einem Produkt kein Rating abgegeben, werden seine Voten zu anderen Produkten mit übereinstimmenden Voten anderer Kunden zu nämlichen Produkten abgeglichen, um von den Voten der anderen auf sein fehlendes schließen und für ihn gegebenenfalls eine Kaufempfehlung aussprechen zu können, bekanntestes Beispiel hierfür ist wohl Amazon.
Apriori-Algorithmus
Auch hier geht es prinzipiell um eine Vorhersage von Ereignissen, bzw. Kundenverhalten. Oben waren es Kundenpräferenzen, die interessengenaue Kaufempfehlungen ermöglichen sollen, der Apriori-Algorithmus wird primär (grundsätzlich eignet er sich für alle in Tabellenform darstellbare Daten) zur Bestimmung wahrscheinlichen Kauf- oder, auf einer Website, Click-/Navigationsverhaltens eingesetzt, was Marketing-/Cross oder Upselling-Aktivitäten nach sich zieht. Als Datenbasis kommen also z.B. Transaktionsdaten aus realen oder virtuellen e-Shop-Warenkörben oder Logfiles in Betracht. In dieser Basis gilt es zunächst, sog. häufige Itemsets/Sequenzen zu finden, in Warenkörben eines Shops hieße das, aus einer beliebigen Anzahl von Datensätzen mit einer beliebigen Artikelmenge bestimmte Häufungen von Produktkombinationen zu finden: der Algorithmus generiert zunächst häufige Objekte, gruppiert diese zu Paaren, findet häufige Paare, dann Dreierkombinationen usw., beispielsweise wäre vorstellbar:
Gemüse, Kartoffeln -> Fleisch, anschließend: Gemüse, Kartoffeln, Fleisch -> Rotwein.
Einen solchen Befund nennt man ein Assoziationsmuster, Berendt, Spiliopoulou, in: Hippner et al. (2002) definieren solche als a) Menge von Objekten, die in einem Nutzungsvorgang zusammen erscheinen, b) Abfolgen von solchen Objekten, wie sie in einem Nutzungsvorgang aufgerufen werden [Hinzukommen des temporalen Aspekts], sowie - hier kommt die Voraussage ins Spiel - c) Wenn-Dann-Regeln, die sich von diesen Mengen ableiten lassen. Letzteres ist für die Identifizierung von Folgekäufen wie "erst Computer, dann Software, dann Hardware, dann weitere Software" eines einzelnen Kunden wichtig. Zur Bestimmung dessen, was überhaupt als häufig bezeichnet zu werden verdient, bedarf es eines Schwellenwertes (Threshold) als Gütemaß, der in diesem Vorgang die Rolle der Abstandsfunktion des k-means Algorithmus einnimmmt: der Support misst den Anteil der Objekte A, B, C, D, ... an allen Nutzungsvorgängen, also:
Transaktionsfolge Gemüse, Kartoffeln, Fleisch, Rotwein / Anzahl aller Transaktionen
und die Konfidenz die Wahrscheinlichkeit, dass aus dem Antecedens "Gemüse, Kartoffeln, Fleisch" auch der Konsequens "Rotwein" folgt: der Support A, B, C, D / Support A, B, C. Der Support bestimmt demnach die Anzahl der Datensätze, die die Regel A, B, C, D enthalten, d.h., er ist ein absolutes Maß, mit dem sich bestimmen lässt, für wieviele Datensätze eine Regel mindestens gelten muss. Die Konfidenz bezeichnet die Anzahl der Datensätze, die der Regel folgen, i.e. der Support, geteilt durch den Support der Voraussetzungen (=dem Antecedens) für den Konsequens D, sie gibt mithin die durch einen Antecedens bedingte Wahrscheinlichkeit für den Aufruf des Konsequens D nach vorausgehenden A, B, C an und ist somit ein relatives Maß zur Bestimmung der Vertrauenswürdigkeit einer Regel. Dabei kann man aber noch nicht ganz ausschließen, dass D nur deshalb als Konsequens einer Assoziationsregel auftaucht, weil es schlicht sehr häufig und damit unabhängig vom Antecedens ist. Dem lässt sich mit Hilfe sogenannter Chi-Quadrat-Tests begegnen, die bestimmen, ob die oben ermittelte bedingte Wahrscheinlichkeit als positive oder negative Korrelation auftritt: in einer zweispaltigen Tabelle (dem "Quadrat") führt die rechte Spalte die Datensätze mit Konsequens, die linke die ohne, den Support s habe ich willkürlich eingetragen:
D | nicht D |
ABC = 3 | ABC = 2 |
D = 8 | Weder ABC noch D = 20 |
Die Zeilensumme der 1. Zeile ist 5, (3/5) / (2/5) > 1, also läge bei diesen (willkürlich verteilten) Supportwerten eine positive Korrelation vor. Dies ist ein nur ein einfaches Muster, tatsächlich gibt es 6 - 7, z.T. hochkomplexe c²-Tests
Sehen wir uns nun die Assoziationsregelentdeckung unter Verwendung dieser Schwellwerte etwas genauer an: er ist anwendbar auf alle Datenbasen in Tabellenform. Gegeben sei z.B. folgende Datenbasis
Nr. | Gekaufte Artikel |
1 2 3 4 5 6 | A, B, C A, C, E B, D, E, F A, D, E A, C, D, E A, D, F |
Für jeden Buchstaben mag man sich einen beliebigen Artikel denken, der dann sein Attribut darstellt, das einen Wert vom Typ boolean besitzt, also "gekauft" oder "nicht gekauft". Somit haben 6 Attribute (A - F) zwei mögliche Werte, es gibt aber für n Artikel 2ⁿ - 1 mögliche Kombinationen, hier also 63, und man kann sich vorstellen, was das für die Performance eines Algorithmus bei Artikelmengen mit Stückzahlen von tausenden oder zehntausenden bedeutet.
Der Ansatz des Apriori-Algorithmus lautet deshalb: besitzt eine bestimmte Menge den spezifizierten Support, so tut das auch jede ihrer Teilmengen. Oder negativ formuliert: erreicht die Menge M den geforderten Support s nicht, schafft das erst recht keine Menge X, die A als Teilmenge enthält. Mathematisch ausgedrückt leuchtet diese Prämisse des Apriori sofort ein: eine Menge M = {m1,..., mn} hat den Support s, also enthalten s Datensätze die Artikelfolge a = {a1,...,an} Innerhalb dieser Folge gibt es selbstverständlich keine Teilfolge, die s unterschreitet, vielmehr das Gegenteil wird zutreffen.
Nun kann man systematisch, d.h., bottom-up, vorgehen. Man überprüft das geforderte s mit einelementigen Attribut-, bzw., wenn die Werte nicht boolean sind (wenn z.B. noch "vorbestellt" ins Spiel käme) Attribut-/Wertmengen, geht über auf Paare, Dreiermengen usw., bis - man erinnere sich an die k-means Cluster - keine Elemente mehr hinzukommen.
Daraus könnte sich folgender Algorithmus ergeben[5] (nach // folgen Erläuterungen):
Eingabe: Daten, Support s |
|
1. C1 = 0 | //Kandidatenmenge - ist am Anfang leer |
2. L1 = einzelne Artikel mit Support ≥ s |
|
3. for i=2, Li-1 <2, i++ { | //i.e. i=i+1; Abbruchbedingung; i++ inkrementiert die Zahl der Elementmengen und schreibt sie in |
4. Ci = Menge der neuen Kandidaten aus Li-1 |
|
5. for (alle Datensätze d) { |
|
6. for (alle c ∈ Ci) { |
|
7. if (c ⊂ d) then count (c) ++; | //c sind diejenigen Daten aus der Gesamtmenge d, die s erfüllen, sie werden um 1 erhöht. |
8. } |
|
9. } |
|
10. Li = {c ∈ Ci | count (c) ≥ s} | // oben in Zeile 3 wird die notwendige Bedingung formuliert, dass in Ci auch nur Elemente gemäß Support s landen, jetzt wird diese Bedingung verifiziert. |
11. } |
|
Ausgabe: Li | // der Algorithmus stoppt, wenn keine neue Untermenge mehr dazukommt |
Schon dieser Algorithmus nimmt bei größeren Datensätzen viel Rechenzeit in Anspruch, da für jede einzelne der Mengen in Li die gesamte Datenbasis durchsucht werden muss. Dieses Problem verschärft sich noch, wenn die Zahl der Attributwerte steigt - und dabei haben wir noch keine einzige Regel gewonnen.
Nehmen wir eine Bücherdatenbank, dem Datenbankeintrag "Buch" sind wieder Attribute zugeordnet, sc. Autor, Genre, Zeit, Ort, Sprache und Attributwerte, also z. B. "Krimi" für das Attribut "Genre". Man beginnt nun mit einer Attribut-Wert-Auswahl nach dem Muster Bottom-Up, also unter der Prämisse, dass eine einfache Attribut-Wert-Kombination ohne hinreichenden Support auch in weiteren Kombinationen nicht genügend häufig auftauchen kann. So arbeitet man sich wieder mit einer einfachen Kombination von Attribut und Wert, also in unserem Beispiel "Genre" und "Krimi" etc. mit hinreichendem Support weiter, bis keine Elemente mehr hinzukommen.
Sprache | Ort | Zeit | Thema | Autor |
deutsch | Stadt | Vergangenheit | Krimi | A. Christie |
englisch | Dorf | Vergangenheit | Krimi | A. Christie |
englisch | Stadt | Gegenwart | Krimi | R. Jones |
deutsch | Dorf | Vergangenheit | Drama | W. Shakespeare |
englisch | Stadt | Gegenwart | Drama | G.B. Shaw |
deutsch | Dorf | Gegenwart | Roman | R. Jones |
Wir wenden völlig korrekte Regeln an, also s = 2 und c =1 (=100%). Wie auf den ersten Blick zu sehen ist, treten in jeder Spalte 2 Attribut Wert-Paare mit s >=2 auf, also insg. 10 Einer-Attribut-Wertmengen, die Zweiermenge enthält 12 Einträge (Sprache = deutsch und Ort = Dorf usw.), die Dreiermenge nur noch 2: Zeit = Vergangenheit und Thema = Krimi und Autor = A. Christie,
Sprache = englisch und Ort = Stadt und Zeit = Gegenwart. Weitere treten bei Support 2 nicht hinzu, damit ist die Erzeugung möglicher Voraussetzungen abgeschlossen und die Regelbildung kann in Angriff genommen werden. Dabei betrachten wir nur die Dreiermengen, da sie am meisten Informationen enthalten. Es ergeben sich 6 Möglichkeiten, 3 mit je 1 oder 2 Einträgen rechts und links der Implikation ->. Da es keinen Datensatz gibt, in dem alle Einträge einen Support von 3 haben und somit auch nicht die Assoziationsregel, die - wir erinnern uns - bei der Konfidenzberechnung im Zähler steht, können sofort diejenigen, die als Antecedens einen Support von 3 haben, ausgeschlossen werden, da sie bei der Konfidenz in den Nenner rutschen und sie so unter die geforderte 1 drücken. Es sind dies Zeit = Vergangenheit und Thema = Krimi als einzelne Antecedenzen. Somit bleiben aus der Dreiermenge:
1. Zeit = Vergangenheit und Thema = Krimi -> Autor = A. Christie
2. Zeit = Vergangenheit und Autor = A. Christie -> Thema = Krimi
3. Thema = Krimi und Autor = A. Christie -> Zeit = Vergangenheit
4. Autor = A. Christie --> Zeit = Vergangenheit und Thema = Krimi
Entsprechend gibt es aus der zweiten Dreiermenge keine einzelnen Antecedenzen, da sie alle je dreimal in der Datenbasis auftauchen und wie oben die geforderte Konfidenz verfehlen. Die Auflistung des Gesamtergebnisses kann an dieser Stelle unterbleiben, da bis hierhin nur Wert auf das procedere gelegt werden soll.
Der Anwendbarkeit der auf diesem Weg beschriebenen Assoziationsregelentdeckung stellt sich allerdings ein Problem in aller Schärfe, das sich an einer so kleinen Datenbasis noch lange nicht mit hinreichender aber doch schon einiger Deutlichkeit exemplifizieren lässt: die Interessantheit der gefundenen Regeln. Der Analyst sucht vor allem nach 2 Arten von Mustern: unexpected und interesting patterns. Bereits in diesem kurzen Ausschnitt fällt auf, dass es mit der Verwertbarkeit der Regeln 1 - 3 nicht allzu weit her ist. Die Quote 1:3 verschlechtert sich mit zunehmender Größe der Datenbasis und es ist eine quälende, demotivierende Tätigkeit des Analysten, in sog. Large Itemsets nach interessanten Mustern zu suchen. Doch ist gerade an dieser Stelle Expertenwissen und -intuition gefragt, die durch keinerlei Automatisierung zu ersetzen sind.
Im kommenden Teil wird die hier vorgestellte Methodik an einem praktischen Beispiel durchgeführt und ausgewertet: die Assoziationsregelentdeckung und Navigationsanalyse an einem Webserverlogfile der c-o-k.
Anmerkungen
[1] S. Hippner, Merzenich, Wilde (2002), S. 4.
[2] Berry & Linoff, 1997, 2000, zit. n. Berendt, Web Mining Seminar III: Data mining techniques and resources, S. 3 (alle Accesses: 15.-18.11.02)
[3] S. dazu Krahl, Windheuser, Zick (1998), S. 52 ff.
[4] s. dazu ausf. www-agrw.informatik.uni-kl.de/damit/m/metrik.html mit gut verständlichem Anwendungsbeispiel, sowie Frank Bensberg, Segmentierung im Online-Marketing, in: Hippner, Merzenich, Wilde (2002), S176ff. Zum Rating-Beispiel cf. Hans-Peter Neeb, Personalisierende Web-Beratungsfunktionen, in: ebd, S. 463 ff.
[5] entn. aus: apriori.ps, www-agrw.informatik.uni-kl.de/damit/team/index.html, Erläuterungen von mir.
Literatur / Links
Daniela Krahl, Ulrich Windheuser, Friedrich-Karl Zick, Data Mining. Einsatz in der Praxis, Bonn 1998.
Hajo Hippner (Hg), Handbuch Web Mining im Marketing : Konzepte, Systeme, Fallstudien, Braunschweig 2002.
Bettina Berendt, HS Web Mining: Analysing Web Information Systems to Enhance Usability and Business Success
Kommentare
Das Kommentarsystem ist zurzeit deaktiviert.
Verwandte Beiträge
Schlagworte
Dieser Beitrag ist den folgenden Schlagworten zugeordnet