
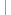
Beiträge
Themengruppen
Recherche
Service
- Was ist Wissensmangement?
- Open Journal of Knowledge Management
- Artikel-Guidelines
- Newsletter
- Kalender
- Wissensmanagement-Anbieter
- Partner
- Mediadaten
Community
Sponsoren

- die Scheidung von falscher und richtiger Information, beim Empfang derselben, bei Problemlösungen und bei unserem Handeln erlaubt.
- ermöglicht, Millionen von Einzelinformationen mit einer einzigen Theorie zu erklären, ohne dass wir uns diese Informationen im Einzelnen merken müssten. Damit ist eine hohe Verdichtung von Informationen möglich.
- in den Stand setzt, Vorhersagen über die Zukunft zu machen, ohne die zielgerichtetes Handeln nicht möglich wäre.
- Wissensgenerierung - sind zusätzliche Experten angeworben, wieviele Experten beschäftigt das Unternehmen, Stand der Dinge in laufenden Lessons Learned-Programmen, abgeschlossene Lessons Learned-Programme.
- Wissensnutzung, gemessen an der Einführung von Wissensträgerkarten, Wissenslandkarten, Abdeckung der Erfassung; Auslastung von Datenbanken und Zugriffszahlen auf das Intranet.
- Wissensverteilung - Auslastung von Groupwaresystemen, Verteilung von Sitzungsprotokollen.
- Wissensbewahrung - Verwaltung der Content Base, Erschließung und Aufbereitung, Aktualisierung des Wissensbestandes auf der Dokumentenebene, Definition von Qualitätsindices.
- Client-/Server-Architektur mit Replikationsfunktion
- Kalender, Aufgabenlisten, Messaging
- Diskussionsdatenbanken (Foren)
- umfangreiche Recherche-Funktionen
- Sicherheitsmechanismen
- Peter Gentsch, Wissen managen mit innovativer Informationstechnologie, Wiesbaden 1999.
- Martin Grothe, Peter Gentsch, Business Intelligence. Aus Informationen Wettbewerbsvorteile gewinnen., München 2000.
- Herwig Rollet, Aspekte des Wissensmanagements (PDF).
- Walther Umstätter, Die Bedeutung der Wissensmessung für das Knowledge Management.
- Projektgruppe GiPP, Ergebnisbericht aus den Projektgemeinschaften Lösungsbausteine für Wissensmanagement-Prozesse
- Ulrike Heid, Ein Konzept für Wissensmanagement.
- Marktübersicht der grossen Wissensmanagement-Systeme
- Herwig Rollet, Knowledge Management Bibliography.
Tools: Herstellerangaben
- Altavier Knowledge Cafe
- USU KnowledgeMiner
Softwareunterstützung im Wissensmanagement
28. November 2001 von Gebhard DettmarDieser Artikel befasst sich mit den Einsatzvoraussetzungen von KM-Tools. Welche Maßnahmen sind erforderlich, um KM strategisch nutzbar zu machen? Wie spürt man vorhandenes Wissen auf, wie gibt man es weiter, wie generiert man neues? Dies sind im groben die Fragen, deren adäquate Behandlung ohne ein zielgerichtetes, genau abgestimmtes Management zum Scheitern verurteilt ist. Anhand mehrerer Beispiele werden die Einsatzmöglichkeiten von KM-Tools exemplarisch vorgeführt und so eine genauere Bewertung ermöglicht.
Einleitung
Knowledge Management ist in aller Munde. Ungeachtet derzeit gängiger Schlagworte wie "Wissensgesellschaft", "Wissenskultur", "Überleben im Informationszeitalter" etc., die auch nicht von ungefähr kommen, verdankt sich dieser Umstand einer konkreten Ausgangslage, der sich ambitionierte Unternehmen an der Schwelle zum 21. Jahrhundert ausgesetzt sehen. Die lautet konkret: Der Globalisierungstrend forciert die Ausweitung inner- und überbetrieblicher Unternehmensnetzwerke, die sich immer effizienter werdender Informations- und Kommunikationssysteme bedienen, dadurch steigt die bewertungsrelevante Datenmenge in exponentiellen Schritten, während die Zahl der Mitarbeiter stetig sinkt und die sogenannten "High Potentials" aggressiven Abwerbungsversuchen ausgesetzt sind. Wenn aber die Antwort auf diese Herausforderungen Knowledge Management lauten soll, muß man sich klar darüber sein, dass dies eine höchst voraussetzungsreiche Angelegenheit ist. Wissen als Unternehmensressource, sogar als die wichtigste? Was ist denn Wissen überhaupt und in welcher Form liegt es in Unternehmen vor? Ist es mess- und qualifizierbar, wenn ja, wie? Welche Maßnahmen sind erforderlich, um es strategisch nutzbar zu machen. Wie spürt man vorhandenes Wissen auf, wie gibt man es weiter, wie generiert man neues? Dies sind im groben die Fragen, deren adäquate Behandlung ohne ein zielgerichtetes, genau abgestimmtes Management zum Scheitern verurteilt ist. Dessen Erfolgsaussichten werden wesentlich durch den gewählten Ansatz bestimmt. Alle Fachleute, die sich mit der Thematik beschäftigen, stimmen in den zwei übergeordneten Kategorien überein, unter das in einem Unternehmen vorhandenes Wissen zu fassen ist: "weiches" = kulturelles, in den Köpfen der Mitarbeiter implizites Wissen und "hartes", also informationstechnologisches Wissen, das durch entsprechende Tools generiert und verteilt wird. In der Diskussion über den besten im Wissensmanagement einzuschlagenden Weg kommen diese Tools erstaunlicherweise schlecht weg. Auffallend häufig wird eine allgemeine Fokussierung auf die technische tool-dominierte Seite kritisiert und die mangelnde Berücksichtigung weicher Komponenten beklagt. Recherchiert man jedoch gezielt nach KM-Systemen und ihrem Leistungsumfang, fällt die Trefferquote weit geringer aus, als dies etwa bei Dokumenten- oder Content Management-Systemen der Fall ist, gleichfalls ist der technische Aspekt gegenüber dem betriebswirtschaftlichen oft unterbetont. Deshalb sollen in diesem Artikel neben den allgemeinen Basisfunktionen eines KMS einmal 2 Tools mit ihren Features etwas genauer vorgestellt werden.
Daten, Informationen, Wissen
Grundvoraussetzung im Wissensmanagement, auch bei der Entwicklung eines entsprechenden Tools, ist es, sich über den genauen Zusammenhang von Daten, Informationen und Wissen klarzuwerden. Francis Bacon (neben vielen anderen), von dem das berühmte Diktum "Wissen ist Macht" stammt, definierte Wissen als "durch Gründe zu wissen." d. h., nicht nur das "dass" (=Information), sondern auch das "warum" (=Wissen) zu kennen. Diese Definition stellt einen entscheidenden Schritt dar auf dem Weg, Wissen von Erfahrung und von Informationen zu scheiden und so eine Flut an Informationen (Stichwort "Information Overload") dadurch zu bändigen, dass man sie kategorisiert, um so zwischen ihnen eine Gesetzmäßigkeit aufbauen zu können.
So weiß ich z. B. schon aus Erfahrung, also einer Summe ähnlicher Informationen, dass ein Glas Wasser herunterfällt, wenn ich es über die Tischkante hinaus schiebe. Wenn ich mich aber in der Newton"schen Gravitationslehre auskenne, stelle ich zwischen der ellipsenförmigen Bahn und Beschleunigung der Gestirne und dem Fall des Wasserglases einen Zusammenhang her, ich setze also zwei voneinander unabhängig auftretende Tatbestände zu einem einzigen zusammen, d. h., aus Sicht der Informatik vernetze ich Informationen mit aus Regeln/Gesetzen gewonnenen Begründungen, was mir die Verarbeitung der Informationssumme ähnlicher Daten aus der Erfahrung erspart und so die Verdichtung/ Kompression von Datenmaterial ermöglicht (vgl. die Kompression von Video-/DVD-Filmen mit MPEG 4). Das hat Auswirkungen auf die Vorhersagbarkeit, auf die Steuerung von Ereignissen. Ohne diese Verdichtung erhalte ich z.B. bei einer Prognose über den Anstieg der Verkaufszahlen eines Firmenprodukts eine Trefferquote von 50%. Erweitere ich gewissermaßen die Variablen, indem ich frage: werden die Verkaufszahlen sinken, stagnieren oder steigen, habe ich bei Unwissenheit nur noch 33% Wahrscheinlichkeit auf meiner Seite.
Ziehe ich nun aus Erfahrung gewonnene Informationen heran, wie z. B.: "im Weihnachtsgeschäft pflegen Umsätze zu steigen", wächst meine Bewertungsgrundlage. Besitze ich darüber hinaus wirtschaftliches Datenmaterial, wie Marktanteile, Kundenbeziehungen etc., lässt sich daraus eine Voraussage tätigen, die die Evidenz auf ihrer Seite hat.
Somit lässt sich über die Definition von Wissen, das durch Knowledge Management Tools nutzbar gemacht werden soll, sagen: Die Qualität und der messbare Nutzen von Wissen ergibt sich aus der Vernetzung von Information und Begründung, die uns
(vgl. Walther Umstätter, Die Bedeutung der Wissensmessung für das Knowledge Management www.ib.hu-berlin.de/~wumsta/lectr.html, S. 3)
Die vom Institut für Wirtschaftsinformatik der Universität Saarland und der Siemens AG gebildete Arbeitsgruppe "Geschäftsprozeßgestaltung mit integrierten Prozeß- und Produktmodellen"
(GiPP ) hat den Übergang von Daten zu Informationen bis zu Wissen graphisch so dargestellt:
|

Entn. aus: "Ergebnisbericht aus den Projektgemeinschaften Lösungsbausteine für Wissensmanagement-Prozesse" w4.siemens.de/zt_pp/ergebnis/b_s3_8.html
Wesentlicher Aspekt dieser Kette ist der hierarchische Aufbau. Dazu schreiben die Autoren der Arbeitsgruppe:
"Daten sind die Grundbausteine der Informationswissenschaft ebenso wie die eines wissensbasierten Unternehmens. Sie sind beliebige Zeichen, bzw. Zeichenfolgen; unstrukturiert und kontext-unabhängig.
Informationen sind zu sinnvollen Strukturen arrangierte Daten. Sie kennzeichnen objektive Inhalte. Zahlen sind beispielsweise Daten, eine Zufallszahlenreihe aber ist eine Information. Informationen sind subjektiv wahrnehmbar und verwertbar.
Der Umgang mit Daten und Information setzt individuelles und kollektives Wissen voraus, denn das Ergebnis der Verarbeitung und Verankerung von Informationen durch das Bewußtsein ist Wissen und somit die höchste informelle Reifestufe in der Hierarchie von Daten, Informationen und Wissen."
Die Aufgaben des Wissensmanagement
Wissen als Ware hat einen wesentlichen Vorteil, den man sich im Wissensmanagement zunutze macht: seine Ausbreitung ist mehrwertbehaftet, das Gesetz der abnehmenden Erträge gilt hier nicht. Dieser Mehrwert aber liegt in der in die Zukunft gerichteten sowohl individuellen als auch kollektiven Handlungsfähigkeit, darüber hinaus der daraus entstehenden Flexibilität gegenüber Anforderungen, die in zu einem zukünftigen Zeitpunkt x entstehen, begründet. Damit wird deutlich, dass die oft behauptete praktische Projektbezogenheit bei der Messbarkeit von Wissen für das Wissensmanagement wenig Sinn macht: seine Bedeutung liegt in der Nutzbarmachung intellektuellen Kapitals für Projekte und Anforderungen, die entweder in der Gegenwart begonnen Auswirkungen auf die Zukunft haben, oder überhaupt erst in der Zukunft entstehen. Das unternehmerische Reaktionsvermögen zu befördern ist der wesentliche Zweck von Wissensmanagement, demzufolge spielt ein KMS eine zentrale Rolle als Planungs- und Steuerungsinstrument strategischer Unternehmensziele.
Ein allgemeiner Anforderungskatalog für Knowledge-Management-Systeme (KMS) ist natürlich immer mit Vorsicht zu genießen und kann nur zu einem groben Überblick über am Markt befindliche Systeme dienen. Eine Marktübersicht erhält man bei den Tools auf dieser Seite. Der individuelle Verwendungszweck eines jeden Unternehmens stellt hierbei die Entscheidungsgrundlage dar und richtet sich nach proprietären Voraussetzungen des einzelnen Unternehmens, wie Infrastruktur, organisationales Umfeld, Aufgabenbereiche der Abteilungen, vorhandenes und nicht vorhandenes Wissen etc. Diese gilt es also vorab zu definieren und zu analysieren, an Hand des so gewonnenen "Wissens über sich selbst" kann man dann ein Pflichtenheft für die zu beschaffende Software erstellen. Doch schon in diesem Vorfeld lässt sich Software sinnvoll einsetzen, wie aus folgendem deutlich wird.
Softwareunterstützung im Wissensmanagement
Bei der Messung intellektuellen und unternehmerischen Kapitals hat sich die Balanced Scorecard weitgehend durchgesetzt. Nicht zuletzt um dem starken Fokus auf rein finanzielle Kennzahlen in den gängigen Steuerungs- und Kontrollsystemen für das Management gegenzusteuern, stellten der Harvard-Professor Robert Kaplan und Unternehmensberater David Norton das Konzept der Balanced Scorecard vor - mit dem Ziel, Unternehmensstrategien genauer definieren und implementieren zu können. Das traditionelle Berichtswesen soll dabei um zunehmend an Bedeutung gewinnende nichtfinanzielle Dimensionen ergänzt werden. Insbesondere sollen die Ergebnisse eine höhere Aussagekraft über die Zukunft eines Unternehmens ermöglichen als dies durch die ausschließliche Verwendung der klassischen und vorwiegend vergangenheitsbezogenen
Kennzahlen der Fall war. Wesentlich ist hier die exakte Definition von Basis-Indikatoren der strategischen Planung bezüglich Kunden, Finanzen, Prozesse und Lernen. Diese können z. B. sein: Kundenzufriedenheit, ROI, Mitarbeiterzufriedenheit, Informationsfluss. Es lassen sich aber auch reine Kernbereiche des Wissensmanagemnts wählen, also z. B.
Natürlich bedürfen die in einer Balanced Scorecard gemessenen Werte der Interpretation durch das Management. Zu diesem Zweck schlagen Kaplan und Norton auch die Visualisierung von Wirkungsketten vor. Sie ist primär ein Messinstrument des Managements, kann aber, unternehmensweit implementiert, wertvolle Unterstützung beim Transport der Unternehmensphilosophie und -ziele leisten.
(vgl. ausführlich dazu Jürgen Weber, Utz Schäfer, Balanced Scorecard erfolgreich einführen., in: Martin Grothe, Peter Gentsch, Business Intelligence. Aus Informationen Wettbewerbsvorteile gewinnen., München 2000, S. 147-157.
Auf dem Konzept der Balanced Scorecard basiert auch das Modell des schwedischen Finanzdienstleisters Skandia, das den Marktwert eines Unternehmens in einer hierarchisch gegliederten Struktur in einzelne Klassen aufteilt und so transparent macht:
|
aus L. Edvinsson and M. S. Malone. Intellectual Capital: RealizingYour Company’s True Value by Finding its Hidden Brainpower.
HarperBusiness, New York, 1997. Entn. v. Herwig Rollet, Aspekte des Wissensmanagements www2.iicm.edu/herwig/thesis/Diplomarbeit_Herwig_Rollett_ONLINE.pdf , S. 136 (PDF).
Damit wird die Balanced Scorecard zu einem wichtigen Werkzeug sowohl in der Einführungsphase als auch in der Bewertung der zuvor definierten Erfolgskriterien.
KMS setzen häufig auf andere Anwendungen, wie z. B. Dokument- und Content-Management-Systeme auf. Insbesondere letztere stellen durch ihre Strukturierungsmöglichkeiten digital gespeicherter Dokumente eine unentbehrliche Voraussetzung im Knowledge Management dar und beinhalten bereits wesentliche Teile der Anforderungen an ein KMS, wie z. B. umfangreiche Retrieval- und Suchfunktionen oder Workflow-Systeme, die den Anwender durch vorgegebene, automatisierte Arbeitsschritte leiten (vgl. dazu Bach, Dettmar und Guretzky auf dieser Seite). Allerdings ist ihr Einsatzgebiet ein anderes. Sie verwalten Inhalte, nicht Wissen, was sie in diesem Bereich anspruchsvoller, aber unflexibler macht, weil sie auf einer strikten Dokumentenstrukturierung aufbauen, was aufwendig ist und für KM nicht immer gilt. In Grundzügen sind CMS und KMS aber häufig gut vergleichbar.
Mit den aus der Dokumentenstrukturierung gewonnenen "intelligenten" Datenbanksystemen lässt sich eine unternehmensweite Wissensbasis (Knowledge Base) datenbankgesteuert anlegen und verwalten. Diese findet Anwendung in verschiedenen, wissensmanagementrelevanten Bereichen, z- B.
Data Warehouse - ein Werkzeug zur Selektion und Speicherung entscheidungsrelevanter Daten zur Verbesserung der unternehmensweiten Informationsversorgung. Dabei handelt es sich um eine für Anforderungen und Rahmenbedingungen spezifische Lösung, ist also kein auf dem Markt erhältliches Produkt von der Stange, sondern bedarf individueller Anpassung.
Zugrunde liegen operative Datenhaltungssysteme - von einfacher Dateihaltung über relationale bis hin zu objektorientierten Datenbanksystemen, die über vordefinierte Importfilter Datenbestände operativ kategorisieren und aufbereiten. Solche Kategorien können z. B. sein:
Umsätze nach Regionen, Umsätze nach Jahren, Umsätze nach Organisationseinheiten oder Abteilungen, Umsätze nach Währungen. Produkte können zu Gruppen zusammengefasst werden usw. Die Steuerung erfolgt über ein Datenbankmanagementsystem (DBMS), dass, wenn es (im Idealfall) mit in XML beschriebenen Daten gespeist wird, eine strukturierte, offene und plattformunabhängige Datenverwaltung erlaubt (s. dazu das Thema des letzten Monats: Content Management - Anforderungen und Nutzen).
Das Konzept des Data Mining existiert bereits seit den 60"er Jahren, die Zahl der Anbieter von Tools ist Legion - von einfachen Desktop-Lösungen bis zu einer unternehmensweiten Client-Server-Netzwerk-Struktur in Multiprozessorumgebung für mehr als 200.000 DM. Die Übergänge vom Data-Mining zur Knowledge-Discovery sind fließend und können hier nicht im einzelnen dargestellt werden.
Der nächste Schritt ist das Erstellen einer Topic- und einer Knowledge Map mit dem Ziel des Information Retrieval. Dafür ist auch das Text-Mining relevant, das sich im Unterschied zum Data-Mining auch auf unternehmensexterne Informationen stützt. Zweck der Übung ist, die sowohl aus Abteilungen und dem Intranet, als auch aus dem Internet gewonnenne Dokumentenbasis nach jeweils relevanten Wissenskategorien zu organisieren, um so die Wissensauffindung und -verbreitung durch Push and Pull zu ermöglichen. Push and Pull machen im Wissensmanagement nur in Kombination Sinn, diese gewährleist, dass eine Informationsversorgung zwar automatisiert erfolgt, aber nicht im Information Overload endet. Das Ganze erfordert ein differenziertes Zusammenspiel von Mensch und Technik in der Definition von Wissensfeldern und der Etablierung einer einheitlichen Begriffsverwendung (Wissenssprache=controlled vocabulary). Ein Beispiel für softwaregestützte Wissenssprachen sind Dokumenttypen in XML. So ist MathML eine DTD (Document Type Definition) zur inhaltlichen Beschreibung mathematischer Sachverhalte, die Algebra durch Browser darstellen lässt oder CML (Chemical Markup Language) eine Sprache, die den Aufbau von Molekülen beschreiben kann. Ein leistungsfähiges Information Retrieval setzt menschliche Einigung über die zu verwendende Terminologie voraus, was sich z. B. aus der Existenz des W3C (World Wide Web-Consortium) ablesen lässt. Insofern spielt die Technik hier auch eine psychologisch unterstützende Rolle, weil Menschen sich häufig erst dann einigen, wenn sie es müssen.
Wer digital gespeicherte Informationen sucht, muss eine Anfrage formulieren und da ist es unabdingbar, eine standardisierte Abfragenterminologie festzulegen, wie das bei automatisierten Abfragesprachen wie SQL oder XML-QL, natürlich auf ganz anderem Level aber prinzipiell vergleichbar, auch geschieht.
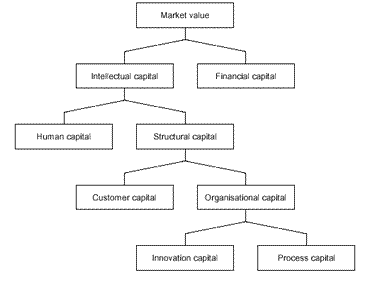
Insgesamt entsteht so ein komplementäres Netzwerk aus implizitem, explizitem und digital gespeichertem Wissen - die Knowledge Base eines Unternehmens.
|
Entn. aus, Herwig Rollet, Aspekte des Wissensmanagements www2.iicm.edu/herwig/thesis/Diplomarbeit_Herwig_Rollett_ONLINE.pdf S. 132 (PDF)
Groupware als Plattform im Wissensmanagement - z.B. Lotus Notes/Domino
Intranets sind prinzipiell herstellerunabhängig. Im Wissensmanagement bieten sich jedoch herstellerbasierte Groupware-Lösungen zum Aufbau eines solchen an, weil sie dazu notwendige Features bereits von Haus aus mitbringen. Als die bekanntesten Hersteller solcher Lösungen sind wohl Microsoft, Netscape, Oracle, Novell und Lotus zu nennen, letztere gilt mit ihrem Produkt Notes/Domino, das hier kurz vorgestellt werden soll, als Marktführer.
Ein wesentlicher Unterschied zu reinen Intranet-Lösungen ist bei Notes/Domino der sogenannte Replikationsmechanismus, der die Aktualisierung von Dokumenten zwischen 2 Kopien einer Datenbank automatisch durchführt. Dabei können räumlich getrennte Organisationseinheiten verteilte Wissensbasen nutzen ohne permanent mit ihnen verbunden sein zu müssen. Veränderungen in den Wissensbasen können so beliebig häufig abgerufen werden.
Zudem ist Notes eine dokumentorientierte Datenbank, die eine medienneutrale Erstellung, Darstellung und Speicherung multimedialer Dokumente erlaubt.
Die Internetfunktionalität aber ist das eigentliche Feature, das Notes/Domino zur offenen Wissensmanagement-Plattform qualifiziert (in vollem Umfang ab Version R5). Da Notes ab dieser Version jedes Dokument über http bereitstellen kann, sind Dokumente aus einer internetbasierten Umgebung, wie es im Knowledge Management eben der Fall ist, problemlos zu verarbeiten. Domino bietet verschiedene Server-Dienste (Web und Mail), er kann alle Dokumente aus Notes-Datenbanken in HTML umwandeln oder deren Inhalte selbst als HTML auffassen und direkt an den Browser weitergeben. Darüber hinaus besitzt Notes eine eigene Entwicklungsumgebung, die es ermöglicht, Applikationen individuellster Art innerhalb des Notes/ Domino-Systems zu programmieren und zu entwickeln. Dazu gibt es zahlreiche Programmierschnittstellen (API) zu unternehmensspezifischen Anwendungen unterschiedlicher Bereiche, wie z. B. MS Office oder SAP R/3. Dabei speichert Notes die für das Information Retrieval vorgesehenen Datenbestände, von den reinen Daten über Formularansichten bis hin zu Workflow-Abbildungen in einem eigenen Datenbankformat und ermöglicht so eine strukturierte Übersicht einer Knowledge Base in jeder beliebigen Aggregationsstufe. Es ist also keine Marketingphrase, wenn Lotus angibt, Version 5 als reines Knowledge Management-Tool entwickelt zu haben. Das System bringt die wesentlichen Funktionen eines solchen Tools, neben oben beschriebenem, bereits mit:
Tools
Es ist nun an der Zeit, hier 2 KM-Tools, die seit einiger Zeit am Markt eingeführt sind und sich eines gewissen Bekanntheitsgrades erfreuen, in ihrem Funktionsumfang dar- und vorzustellen: der KnowledgeMiner der USU AG und Knowledge Cafe von altavier.
Letzteres ist ein intranetbasiertes, modular aufgebautes und somit skalierbares Tool, das aus den Komponenten Yellow Pages, Virtuelle Bibliothek, Knowledge Base, Presse,
MyNews, BlackBoard, Projekte, Workflow und Diskussion besteht. Die Module verwenden die übergreifenden Funktionen Glossar, MyBookmarks, Online-Hilfe und GlobalSearch. Voraussetzung hierfür ist ein Unternehmensintranet, in dem den als Wissensträger ausgewiesenen Mitarbeitern persönliche Hompages - Yellow Pages - zur Verfügung stehen. Damit entsteht ein Mitarbeiterpool, der Auskunft gibt über Arbeitsschwerpunkte, individuelle Kompetenzen, Projekterfahrungen etc., also die Auffindung geeigneter Ansprechpartner für bestimmte Probleme oder Teilnehmer an zu gründenden Projektteams ermöglicht.
Die virtuelle Bibliothek ist im wesentlichen ein Dokumenten-Management-System, das der Archivierung und Indizierung gespeicherter Unternehmens-Datenbestände dient, dazu die Zugriffsberechtigung für die Veröffentlichung neuer Dokumente an einige wenige Redakteure delegiert. Die Knowledge Base dient demgegenüber als Datenpool für alle Mitarbeiter, doch kann man auch hier Zugriffsbeschränkungen realisieren, womit der Unterschied zur Bibliothek ein wenig verschwimmt. Das Diskussionsmodul bietet die Plattform für den Meinungsaustausch entstandener Expertenforen, der so themenbezogen auf verschiedenen Ebenen erfolgen und die Wissensverteilung im Unternehmen befördern kann. Die Module Presse und MyNews versorgen Mitarbeiter mit für sie relevanten Medien- und Newsgroupinformationen - Stichwort Push and Pull. Projekte baut auf üblichen Groupware-Funktionalitäten (Teamkalender, Mail, Ressourcenverwaltung und Aktivitätenplanung) auf und bietet darüber hinaus einen Ablagebereich der entstandenen Dokumente (Arbeitspapiere, Meilensteine, Erfahrungs-/Projektberichte, Ergebnisse), der verteiltes Arbeiten mit schnellem Zugriff ermöglicht. Über Zugriffsbeschränkungen in diesem Bereich schweigt sich altavier aus. Hervorzuheben ist die Workflow-Komponente. Auf Basis individuell konfigurierbarer Modelle ermöglicht sie die Abbildung der Geschäfts- und Arbeitprozesse des Unternehmens und seiner Mitarbeiter im Intranet. Dabei sind alle Module von Knowledge Cafe miteinbeziehbar - eine wissensbasierte Unterstützung des jeweiligen Arbeitsschrittes ist also möglich. Auch das Glossar erfüllt eine wichtige und häufig vernachlässigte Funktion: es sorgt im Unternehmen für eine einheitliche semantische Basis, eine Art Begriffs-Administration. Dies ist, s. oben, für eine sinnvolle Formulierung von Suchanfragen und somit für das Erreichen relevanter Treffer unerlässlich. In einer eigenen Datenbank werden typische Begriffe aufgenommen, erläutert, mit Synonyma versehen und so nach einer mehrstufigen Verschlagwortung semantisch eingeordnet. Dies erfordert natürlich eine eigene Pflege, ein solcher Aufwand ist jedoch dringend anzuraten.
Das Tool basiert auf der oben beschriebenen Lösung Lotus Notes/Domino, ist dabei jedoch unabhäng von Notes als Client (was für Domino-Datenbanken, s. oben, prinzipiell auch gilt). Dank des http-Protokolls ist es auf jeder Plattform, die über einen Browser verfügt, einsetzbar.
Der USU KnowledgeMiner ist ein ebenfalls modular aufgebautes Tool zur Themenstrukturierung und Vereinheitlichung des Informationszuganges in heterogenen IT-Umgebungen. Als einziges User-Interface (GUI) kennt der KnowledgeMiner den Browser, die Einstellungen sind flexibel anpassbar dank des Einsatzes von XML und XSL.
Der Clou des Systems besteht zweifellos in der Organisation seiner Topic Maps, die in der (schreibfehlertoleranten) Fuzzy-Suche erscheinen. Aus bestehenden Datenquellen extrahiert es Meta-Daten, die sich so semantisch vernetzen lassen, woraus ein hierarchisch aufgebauter Knowledge Tree erstellt wird. Damit lässt sich von einem zentralen Ausgangspunkt zu immer genaueren Eingrenzungen des Suchbegriffs fortschreiten. Dazu gibt es Querverweise zu Themen, die mit dem Suchbegriff in erkennbarem Zusammenhang stehen. So gelangt man beispielsweise ausgehend vom Suchbegriff "Motor" zu Otto-/Diesel- oder Elektromotor, als Querverweise findet man die Kardanwelle o. ä., bis sich zu einem einzigen Suchbegriff ein Überblick über das Themengebiet ergibt, aus dem der Begriff entstammt. Dies lässt sich beliebig fortsetzen über einen Themenkontext bis zu einem Gesamtbild, an dessen Anfang ein einziges Suchwort stand. Bei der normalen Suche werden von den gespeicherten Dokumenten Abstracts erstellt, die dem Anwender eine schnelle Beurteilung ihrer Relevanz erlauben. Ähnlich dem altavier-System können auf dem Messenger vordefinierte Interessenprofile abgelegt werden, die seine News-Versorgung entsprechend dem Push and Pull-Prinzip auf Relevanz ausrichtet (NewsCaster-Funktion). Bestand die Skalierbarkeit bei Knowledge Cafe im Clustern mehrerer Domino-Server, ist die Architektur bei dem USU-Tool komplett javabasiert und damit beliebig skalierbar.
Die Preise beider Systeme richten sich nach dem Umfang der einzeln lizensierbaren Module und der Anzahl der Clients. Dazu kommen Wartungsverträge und individuelle Anpassungen. Es ist daher sinnvoll, sich diesbezüglich an die Hersteller zu wenden.
Ausblick
KMS-Tools können eine wichtige Rolle in der Untersützung eines unternehmensweiten Knowledge Managements übernehmen. Die besprochenen Tools haben bezüglich Wissensgenerierung und Retrieval einiges zu bieten - allerdings setzen beide ein aktiv betriebenes Wissensmanagement der einbezogenen Abteilungen voraus, wie der Aufbau der Suchfunktionen und der Informationsfilterung bei beiden Systemen noch einmal deutlich machte - die Definition der Suchbegriffe, überhaupt der zu verwendenden Terminologie erfolgt immer noch vom Menschen. Dann allerdings ist die Lernfähigkeiten der Systeme erstaunlich. Hier zeigt sich, welcher Fortschritt bezüglich Automatisierung der Wissensgenerierung mit gezielt eingesetztem Aufwand auf technischer Seite möglich ist. Der vielbeschworene Wandel zur lernenden Organisation gelingt jedoch - darauf sei an dieser Stelle noch einmal verwiesen - nur unter einem ganzheitlich betriebenen und interdisziplinär ausgerichteten Management, das die spezifischen Faktoren der Ressource Wissen in ihren je eigenen Bestandteilen analysiert und erfasst. Das ist ein langer Weg mit einer sehr heterogen zusammengesetzten Gruppe von Beteiligten, denen z. T. ein grundlegendes Umdenken, eine sehr weitgehende Einstellungsänderung bezüglich der eigenen Position im Unternehmen und dem Umgang mit dessen wertvollster Ressource abverlangt werden. Schnelle Erfolge wären hier gerade auch im Hinblick auf Überzeungsarbeit und Motivationssteigerung wünschenswert, dabei sind sie auf diesem Gebiet nicht immer realistisch. Doch geben die bei beiden Systemen beobachteten Möglichkeiten der Skalierbarkeit von Wissen via Information Retrieval auch auf diesem Gebiet durchaus Anlass zu etwas mehr Optimismus.
Literatur
Eine umfangreiche Bibliographie zum Thema findet sich unter:
Kommentare
Das Kommentarsystem ist zurzeit deaktiviert.
Schlagworte
Dieser Beitrag ist den folgenden Schlagworten zugeordnet