
Beiträge
Themengruppen
Recherche
Service
- Was ist Wissensmangement?
- Open Journal of Knowledge Management
- Artikel-Guidelines
- Newsletter
- Kalender
- Wissensmanagement-Anbieter
- Partner
- Mediadaten
Community
Sponsoren

Knowledge Discovery in Databases, Teil IV: Der Web Utilization Miner WUM
14. Oktober 2004 von Gebhard DettmarDer WUM (Web Utilization Miner) wurde entwickelt, um dem Analysten Möglichkeiten der gezielten Abfrage seiner Daten unter Einbeziehung entscheidungskritischer Parameter zu ermöglichen und Unzulänglichkeiten in der Abfrage gegenwärtig verbreiteter Web Mining-Tools zu begegnen. Die dazu notwendigen Voraussetzungen in der Datenaufbereitung wurden in den vorausgehenden Teilen, KDD, Teil 2 und 3, beschrieben, das dem Data Mining-Anstatz entsprechende grundlegende methodische Verständnis insbesondere des Apriori-Algorithmus zur Assoziationsregelentdeckung in KDD, Teil 1. Damit sind wir in der Lage, ein unseren Anforderungen entsprechend aufbereitetes Webserverlog in WUM zu importieren und so zu analysieren, dass sowohl die Stärken wie auch unerwartete Schwachstellen im Design unseres Webauftrittes erkannt und behoben werden können. Im folgenden wird die Arbeit mit WUM beispielhaft vorgeführt, so dass jeder, der diese Serie aufmerksam verfolgt hat, in die Lage versetzt sein sollte, beliebig große und komplexe Webserver-Logfiles mit WUMprep aufzubereiten und mit WUM zu analysieren.
Einleitung
Der WUM (Web Utilization Miner) wurde entwickelt, um dem Analysten Möglichkeiten der gezielten Abfrage seiner Daten unter Einbeziehung entscheidungskritischer Parameter zu ermöglichen und Unzulänglichkeiten in der Abfrage gegenwärtig verbreiteter Web Mining-Tools zu begegnen. Die dazu notwendigen Voraussetzungen in der Datenaufbereitung wurden in den vorausgehenden Teilen, KDD, Teil 2 und 3, beschrieben, das dem Data Mining-Anstatz entsprechende grundlegende methodische Verständnis insbesondere des Apriori-Algorithmus zur Assoziationsregelentdeckung in KDD, Teil 1. Damit sind wir in der Lage, ein unseren Anforderungen entsprechend aufbereitetes Webserverlog in WUM zu importieren und so zu analysieren, dass sowohl die Stärken wie auch unerwartete Schwachstellen im Design unseres Webauftrittes erkannt und behoben werden können. Im folgenden wird die Arbeit mit WUM beispielhaft vorgeführt, so dass jeder, der diese Serie aufmerksam verfolgt hat, in die Lage versetzt sein sollte, beliebig große und komplexe Webserver-Logfiles mit WUMprep aufzubereiten und mit WUM zu analysieren. Dabei wird Wert auf die theoretischen Voraussetzungen der praktischen Arbeit gelegt, denn Web Mining ist ein Gebiet, in dem man ohne Theorie nicht weit kommt. Für Probleme, Fragen und Anregungen steht allen Interessierten das Forum offen.
Die Architektur des WUM
Der Ansatz, der dank seiner Umsetzung in WUM den Vorsprung dieses Tools begründet, ist die von Spiliopoulou und Faulstich 1998 eingeführte generalisierte Sequenz, auf die die WUM Query Language MINT ansetzt: sie dient der Sichtbarmachung von Navigationsmustern (Navigation Patterns) in einer aggregierten Ansicht des zugrundeliegenden Logfiles eines Webservers. Über MINT können Anwender genau die Patterns abfragen, die die gewünschten Charakteristika aufweisen, während solche von geringem Interesse außen vor bleiben können. Die g-sequence beschreibt dabei eine Sequenz von Abrufen, die den Analysten interessiert: eine Sequenz ist dabei eine Abfolge von Seitenaufrufen.
Eine solche bestehe aus den Seiten A, B, D, E. Interessiert sich der Analyst nun nur für die Seiten A und E (weil diese Seiten in seiner Taxonomie eine Rolle spielen), legt er diese als Eckpunkte seiner Anfrage fest und bestimmt mit Hilfe einer Wildcard, wie viele Zwischenaufrufe in dieser Sequenz vorkommen dürfen. Damit eignet sich das Tool speziell für die Auswertung des Navigationsverhaltens von Portal-/eShop- kurz allen Webauftritten, die sehr umfangreich sind, da Abfragen problemorientiert und entscheidungskritisch vorformuliert gestellt werden und sich daraus ergebende Resultate zu einem erfolgsversprechenden Redesign verwendet werden können. Denn je umfangreicher eine Seite, desto wichtiger ihre Struktur und genau darauf zielt WUM ab: auf die Optimierung der Struktur.
Er besteht im wesentlichen aus 2 Modulen: dem Aggregation Service und dem MINT-Prozessor. Ersterer extrahiert Informationen über die Aktivitäten der Portalbesucher und erstellt über deren Folgeaktivitäten Transaktionsmuster, die in besagte Sequenzen transformiert werden. Diese Sequenzen lassen sich nun in einer Baum-Struktur, dem Aggregate Tree, darstellen, der in einem aus dem Tree resultierenden verdichteten Aggregation Log statistisch verwertbares Material über Nutzer-Bewegungen zur Verfügung stellt. Dies sieht in der Praxis so aus:
Nach dem Import eines Logs, das alle Phasen des Preprocessing (s. KDD II und III) durchlaufen hat, generiert WUM ein Aggregated Log als Datenbasis. Der Nutzer erhält die Meldung:
356 trails have been aggregated in the aggregated log (database).
The aggregated log consists of 163 observations (i.e. branches)
and 79 children of the root node (root support = 356).
Dies heißt konkret: er hat in 356 Visitor-Sessions 163 Beobachtungen (observations) gemacht, d.h., er macht prinzipiell folgendes: aus angenommenen drei Folgen von Seitenabrufen (= Navigation Patterns, Support in Klammern): a-b-e (6), a-b-e-f (3) und b-d-b-c (2) erstellt er diesen aggregrated tree:
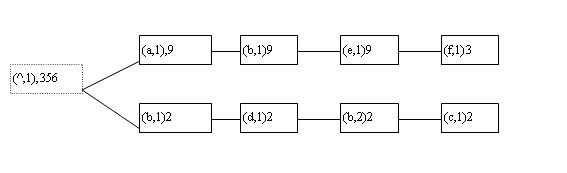
Abb. 1: aggregated tree, angelehnt an [Sp99]
Wie man sieht, hat er, ausgehend vom Root Node, i.e. den 356 Sessions, zwei der drei Navigationsmuster zu einem "verdichtet", da sie denselben Startpunkt, Seite a, haben. Der Support der beiden Muster, der bis e gleich ist, also im Beispiel 9 beträgt, ist hinter Präfix und Occurrence angegeben, d.h., gäbe es noch einen Pfad b,f,d (3), erhielte das erste b im unteren Pfad einen Support von 5 und von ihm ginge ein neuer Pfad mit f und d aus. Besonderes Augenmerk sei bereits hier auf die "Occurrence" gerichtet, die wiederholte Seitenabrufe offen legt. Wir werden in der Analyse sehen, inwiefern das ein wesentlicher Vorteil von WUM ist.
Auf dieses aggregated log setzt MINT auf. Die Abfragesprache fungiert als Schnittstelle zwischen Anwender und Miner, indem sie Fragen erlaubt, die spezifische vorformulierte Kriterien enthalten. Das setzt voraus, dass der Anwender Hintergrundwissen über statistische und mining-spezifische Methoden besitzt, somit ist WUM kein Expertensystem. Dieses Hintergrundwissen besteht im wesentlichen aus Kenntnissen über die Anwendung der Sortieralgorithmen, die im ersten Teil dieser Serie beschrieben wurden. Sie werden in [SC 2001] et al. für die Auswertung von Webserverlogs nutzbar gemacht (vgl. Teil III)
MINT kennt 2 Anwendungsmodi: als Notifier führt sie vordefinierte Abfragen periodisch aus, als Explorer erlaubt sie konkrete ad-hoc-Abfragen. Ersterer ist nützlich für die Überprüfung von Erwartungen an das Nutzerverhalten, bzw. die Feststellung von Abweichungen, letztere erlauben situationsbezogenes Abfragen bei neu auftauchenden Problemstellungen.
Seine eigentliche Stärke aber entfaltet der Miner im Zusammenspiel mit WUMprep (s. KDD, Teil III). Eine Site besteht aus verschiedenen Pages, die jedoch ungeachtet ihrer Verschiedenheit eine gemeinsame übergeordnete Bedeutung besitzen. Klassifiziert man sie unter diesem Gesichtspunkt (sc. indem man eine Ontologie zur Seitenbeschreibung erstellt), lassen sich auch eine größere Anzahl von User-Sessions (zusammenhängende Visits) dergestalt ordnen. Davon profitiert eine ganze Reihe weiterer Analysemöglichkeiten: die Erstellung von Assoziationsregeln nach dem Muster der Warenkorbanalyse (s. KDD, Teil I), einheitliche Navigationsstrukturen durch Anpassung des Designs an das tatsächliche Nutzerverhalten etc. Hat man diese Ontologie erstellt, kann die Klassifizierung der Pages (semi-)automatisch erfolgen: ein maschinell lernender Algorithmus operiert auf Basis der Beschaffenheit von HTML-Code und seinem Vokabular. Der nächste Schritt ist die Generierung von Konzepthierarchien, in die man die Session-Pfade nun unterteilen kann. Die Hierarchie verläuft nach der taxierten Bedeutung der Pages. In KDD Teil III wurde eine solche Konzepthierarchie erstellt und erläutert.
Damit sind wir bei der kombinierten Verwendung von WUMprep und WUM: die Anwendung der Assoziationsregelentdeckung auf ein Webserverlog wird in [SC2001] beschrieben und in KDD III erläutert: zunächst ermittelt man die Kontakteffizienz einer Action Page, also ihren Support, dann die relative Kontakteffizienz, also ihre Konfidenz. Genauso verfährt man mit der Konversionseffizienz Sa = Pa --> Pt (= Action-Page --> Target-Page, s. KDD III), die nichts anderes als die Konfidenz einer Assotiationsregel ist. Die via regexpr.txt und mapReTaxonomies.pl entstehenden URLs aller Action- und Target-Pages der c-o-k sieht man im Link aus Teil III: www.c-o-k.de/pdf/regexpr.txt.
Zunächst interessiert uns die Kontakteffizienz der Action Pages. Diese ermitteln wir aus Effizienzgründen ohne MINT-Abfragen:
e Unterteilung in Sessions wird eigentlich mit sessionize.pl aus WUMprep erzeugt. Allerdings kreiert dieses Script zufällig gewählte SessionIDs, um Konflikte beim Merging mit anderen Logfiles zu vermeiden. Deshalb erkennt man aus dem mit sessionize.pl erzeugten mylog.sess nicht ohne weiteres die tatsächliche Anzahl der Sessions. awk schafft hier Aufschluss:
awk "{print $1}" mylog |sort -u |wc -l
liefert die Zahl der enthaltenen Sessions.
Grept man nun nach "ACTION", erhält man gemäß der Definition aus [SC 2001] die Anzahl der "active sessions". In meinem c-o-k-Log ist das 179 / 377 = 48%, die Anzahl der Sessions erhalte ich mit:
grep ACTION mylog | awk "{print $1}" |sort -u |wc -l
Anschließend wird die relative Kontakteffizienz für jede einzelne Action Page ermittelt, für die ich nun lediglich ACTION mit dem jeweiligen String einer Action Page ersetze.
Das dauert in WUM zu lange, ein Shellscript ist hier schneller:
#! /bin/sh
grep ACTION mylog |awk "{print $7}" |sort -u > actionpage.log
for i in "cat actionpage.log"; do
echo -n "$i: "
grep "$i" mylog |awk "{print $1}" |sort -u |wc -l
done
Das Script[1] liefert mir jede einzelne Actionpage mit Angabe der Anzahl der Sessions, in der sie auftaucht. Für die relative Kontakteffizienz benötige ich also deren Summe geteilt durch die Anzahl der jeweiligen Sessions. Das Ganze will ich als fertig formatierte Tabelle mit Angaben in Prozent haben. Ich schreibe den Output des Shellscripts in eine Datei und übergebe an awk[2]:
#!/bin/awk -f
{ sum += $2; line[n++] = $0 }
END {
print "total sum =", sum;
for (i=0; i<n; i++) {
split(line[i], f);
printf("%-30s %3d : %5.2f%%\\n", f[1], f[2], f[2] / sum * 100);
}
}
Das liefert mir folgende Liste:
ACTION_FALLSTUDIEN: | 26 | 8,50% |
ACTION_HOME: | 97 | 31,70% |
ACTION_HOME1: | 14 | 4,58% |
ACTION_HOME_WEITERLEITUNG: | 1 | 0,33% |
ACTION_INDEX: | 79 | 25,82% |
ACTION_ITLEITER: | 5 | 1,63% |
ACTION_KONTEXT: | 2 | 0,65% |
ACTION_KOORDINATOR_WM: | 5 | 1,63% |
ACTION_METHODEN: | 18 | 5,88% |
ACTION_ORGANISATIONSENTWICKLER: | 10 | 3,27% |
ACTION_PERSONALENTWICKLER: | 4 | 1,31% |
ACTION_QUALITAETSMANAGER: | 7 | 2,29% |
ACTION_ROLLEN: | 1 | 0,33% |
ACTION_SUCHE: | 16 | 5,23% |
ACTION_WERKZEUGE: | 21 | 6,86% |
Im Prinzip könnte man sich also, so man über ein mit WUMprep gemapptes Log verfügt, daraus schon einen simplen Web Usage Miner basteln, der für jede Action Page die relative Kontakteffizienz und mit einer Erweiterung, die $1 aus dem actionlog übernimmt (also Sessions, von denen wir wissen, dass sie Action-Pages enthalten), und nach TARGET greppt, auch die jeweilige Konversionseffizienz einer Action Page ausgibt. Das machen wir jedoch besser in WUM, da wir hier auf Wildcards und Occurrences zurückgreifen können.
Dazu benötigen wir für den Import in WUM ein Log, das die Action Pages nach dem Muster der regexpr.txt in obenstehendem Link enthält, während alle Target Pages unter demselben URL auftauchen sollen, sc. TARGET. Das geht in unserer regexpr.txt z.B. im vi mit
:%s/^TARG[A-Z_&0-9]*/ TARGET/
Doch zunächst die rel. Kontakteffizienz im Überblick:
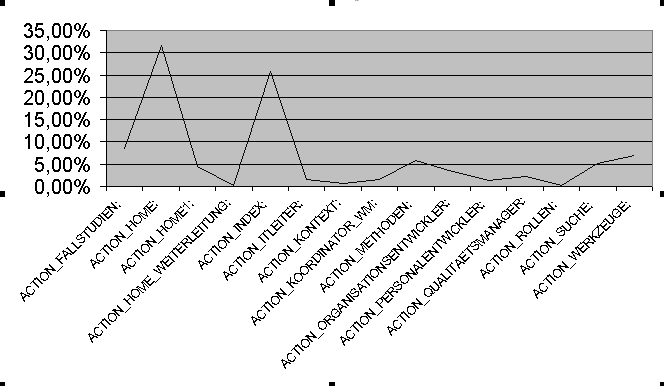
Abb. 2. rel. Kontakteffizienz Action-Pages
Man sieht, dass ACTION_INDEX, unsere Schlagwortuche, nach oben ausbricht. Wir werden sehen, was es damit auf sich hat.
Die Arbeit mit WUM
Zur Installation, Logfile-Importen und der Erstellung der (aggregierten) Mining Base findet man hier alle benötigten Instruktionen. Dazu nur zwei Anmerkungen: man sollte als Tuning-Maßnahme im Shellscript wumgui unbedingt den Java Heap um die Größe des verfügbaren Arbeitsspeichers hochsetzen, z.B.: SET WUM_JAVA_OPTIONS=-classic -ms64m -mx512m -ss4m -oss8m
Zudem verkraftet das in WUM implementierte Weka keine &- und %-Zeichen. Will man also einen Association Rules-Report erstellen, müssen (z.B. mit s/[%&]/-/g) diese Zeichen vor dem Import in Hyphen oder Ähnliches ersetzt worden sein. Vergisst man das, kann man sich die Assoziationsregeln mit MINT erzeugen:
select t
from node as a b, template a * b as t
where a.support > 5
and (b.support / a.support) > 0.3
Wir sehen hier die Struktur von MINT: die generalisierte Sequenz a -> beliebig viele Seiten -> b wird zu Beginn als Template festgelegt, für das anschließend die Variablen gemäß den Wünschen des Analysten spezifiziert werden können[3].
Wir beginnen mit den Übersichts-Informationen, die WUM in seinen Reports zur Verfügung stellt, und die an Tools wie Analog oder Webalizer erinnern: die WebSitePages liefern den Support unsrer Action- und Target-Pages, und das sind wichtige Kenngrößen für uns:
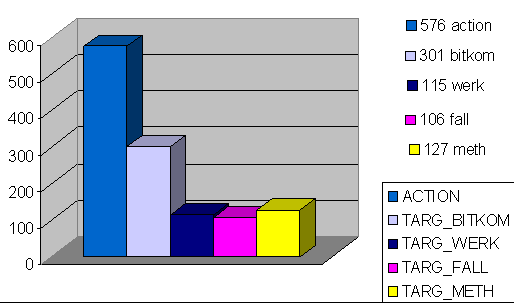
Abb. 3. WebSitePages: Support Action- und Target Pages
Wir sehen einen hohen Wert für Bitkom, zwar vereinigen diese Artikel auch alle drei Kategorien, Werkzeuge, Fallstudien, Methoden in sich, doch das ändert nichts daran, dass diese Artikel mit Abstand die beliebtesten sind: auch der Mittelwert der Seitenaufrufe überragt die anderen bei weitem. Die Kategorien selbst liegen nahezu gleichauf, was bei ihren Action Pages nicht der Fall gewesen ist. Ferner ist zu berücksichtigen, dass die Zahl der unter Methoden kategorisierten Artikel auf der c-o-k die der beiden anderen Kategorien bei weitem überragt: in dem dieser Untersuchung zu Grunde liegenden Ausschnitt beträgt die Anzahl der Seitenabrufe TARGET_METHODEN 58, FALLSTUDIEN 28 und WERKZEUGE 22. Sehen wir uns noch einmal die rel. Kontakteffizienz der drei Kategorien an:
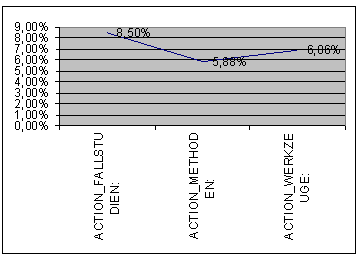
Ziemlich genau so sieht das aus, wenn man nur den Support nimmt. Vergleichsweise wenig Aufrufe von METHODEN führen also zu häufigen Aufrufen von Targetpages. Berechnen wir die Konfidenz nach dem Muster der Assoziationsregelentdeckung aus Teil I, also Support der Sessions, die Antecedens (=ACTION_METHODEN) + Konsequens (=TARGET_METH) enthalten, geteilt durch Support Antecedens mit Hilfe obigen Shellscripts, ergibt sich:
Methoden = 23%, Werkzeuge = 13%, Fallstudien = 7%.
Das überrascht auch nicht weiter, da ACTION_METHODEN am seltensten aufgerufen wurde, aber mit Abstand die meisten Seiten anbietet (s.o.). Diesen Vorabbefund schauen wir uns nun in WUM genauer an:
Zu diesem Zweck fragen wir sie alle drei nach dem gleichen Muster ab: zunächst erlauben wir in einer Mining Base, die alle Artikel nur nach ihrer jeweiligen Kategorie referenziert[4], beliebig viele Seitenaufrufe nach a, denn wir haben unter den sortierten Ergebnislisten der jeweiligen Kategorie bis zu 18 Trefferseiten (Methoden), es kann also gut sein, dass jemand erst nach der 10. Seite in Methoden auf die Targetseite stößt, die ihn interessiert, und dies ist aus unserer Sicht kein unerwünschtes Navigationsverhalten - Beschränkungen über Wildcards machen hier also keinen Sinn, sehr wohl aber solche zur Konfidenz:
select t
from node as a b, template a * b as t
where a.url = "ACTION_METHODEN"
and b.url = "TARG_METH"
and a.support >= 5
and (b.support / a.support) = 0.3
dito für Fallstudien und Methoden. Diese drei Abfragen speichern wir als Mint Batch Query, i.e. als querFall.wbq usw. Als Output geben wir querFall.wq an, entsprechend für Werkzeuge und Methoden. Daraufhin schließen wir die Mining Base und erstellen eine neue, diesmal mit allen aufgeführten Targetpages, also aus einem Log, das mit der regexpr.txt aus obigem Link erstellt wurde. Erneut gehen wir die 3 Kategorien durch, diesmal mit der Frage
select t
from node as a b, template a * b as t
where a.url = "ACTION_METHODEN"
and b.url startswith "TARG"
and a.support >= 5
and (b.support / a.support) = 0.3
Wir schreiben 2 batch Files, die die Batch Queries ausführen und widmen uns anderen Dingen. Diese Vorgehensweise empfiehlt sich insb. bei größeren Logs, bei denen eine MINT-Abfrage schon etwas dauern kann. Ansonsten sind batch queries für periodisch immer gleiche Abfragen gedacht, der ad hoc Prozessor sagt schon im Namen, wofür man ihn verwendet, nämlich für aus den periodisch durchgeführten Fragen sich ergebende Hinweise, die man der Weiterverfolgung für wert erachtet.
Die Abfrage zu allen drei zeigt ein relativ konstantes Navigieren durch die sortierten Ergebnisse und Artikelabrufe in der ausführlichen Target-Mining Base. Die einzige Seite, die eine Konfidenz > 30% schaffte, waren WERKZEUGE. In der "Target-nur-Kategorien-Mining Base" dagegen stehen WUM mehr Merging Points zur Verfügung, man erhält insgesamt längere Pfade. Hier sehen die aggregated trees völlig anders aus:
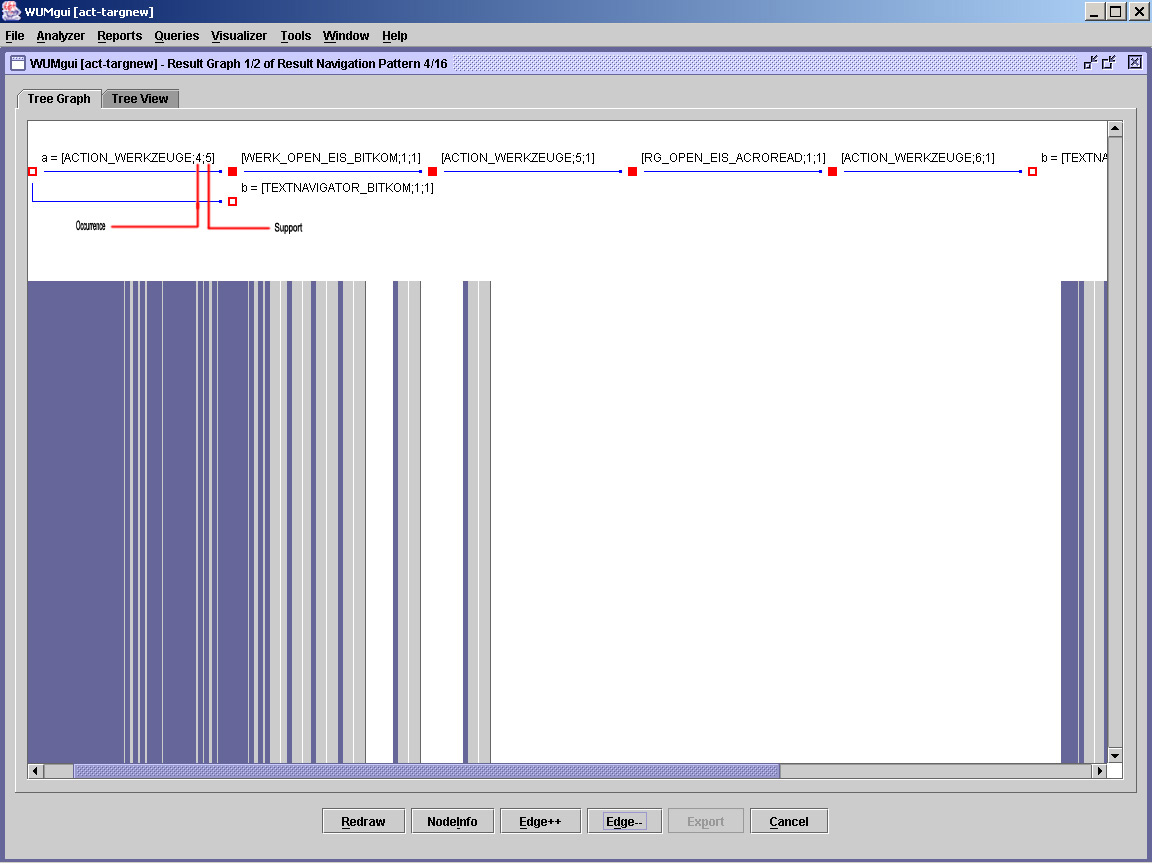
Abb. 4. ACTION_WERKZEUGE mit ausf. Target Pages
Hier sehen wir 5 Besucher, von denen 2 gemäß dem vorgegebenen Template (a = Werkzeuge, b = Target Page, dazwischen beliebig viele Seitenabrufe) navigieren. Die restlichen Navigation Patterns werden von Wum nicht angezeigt - sie sind durch die Einschränkungen der where clauses ausgeschlossen. Beide starten von der 4. sortierten Werkzeug-Seite, User b erreicht sein Ziel sofort, User a auch. Doch a geht zurück auf die 5. Trefferseite der Action Page und ruft dann die pdf des Bitkom-Artikels auf. Das heißt, er verschmäht die Treffer der 5. Seite und benutzt den Back-Button seines Browsers, um von der Open EIS Bitkom-html Version die zugehörige pdf aufzurufen, die den kompletten Artikel enthält. Andernfalls könnte zwischen "WERK_OPEN_EIS_BITKOM" und OPEN_EIS_ACROREAD (wie aus der regexpr.txt ersichtlich die volltändige pdf-Version) keine Seite liegen. Dann geht er auf die 6. Trefferliste und ruft TEXTNAVIGATOR_BITKOM, ebenfalls eine Werkzeugseite, auf. Für die Frage lieferte Wum 16 Patterns.
Wir schauen uns nun die Batch-Queries aus der Mining Base, die alle Target Pages als TARG_WERK /-FALL und METH enthält, an. Hier beträgt die Trefferquote für Werkzeuge 23, die Pfade sehen ähnlich aus

Abb. 5 ACTION_WERKZEUGE nur TARGET
Das allerdings ändert sich bei ACTION_METHODEN. Sie brachten mit obiger Abfrage (Konfidenz > 30%) nur 2 Patterns, das Abbild zeigt PatternID 1
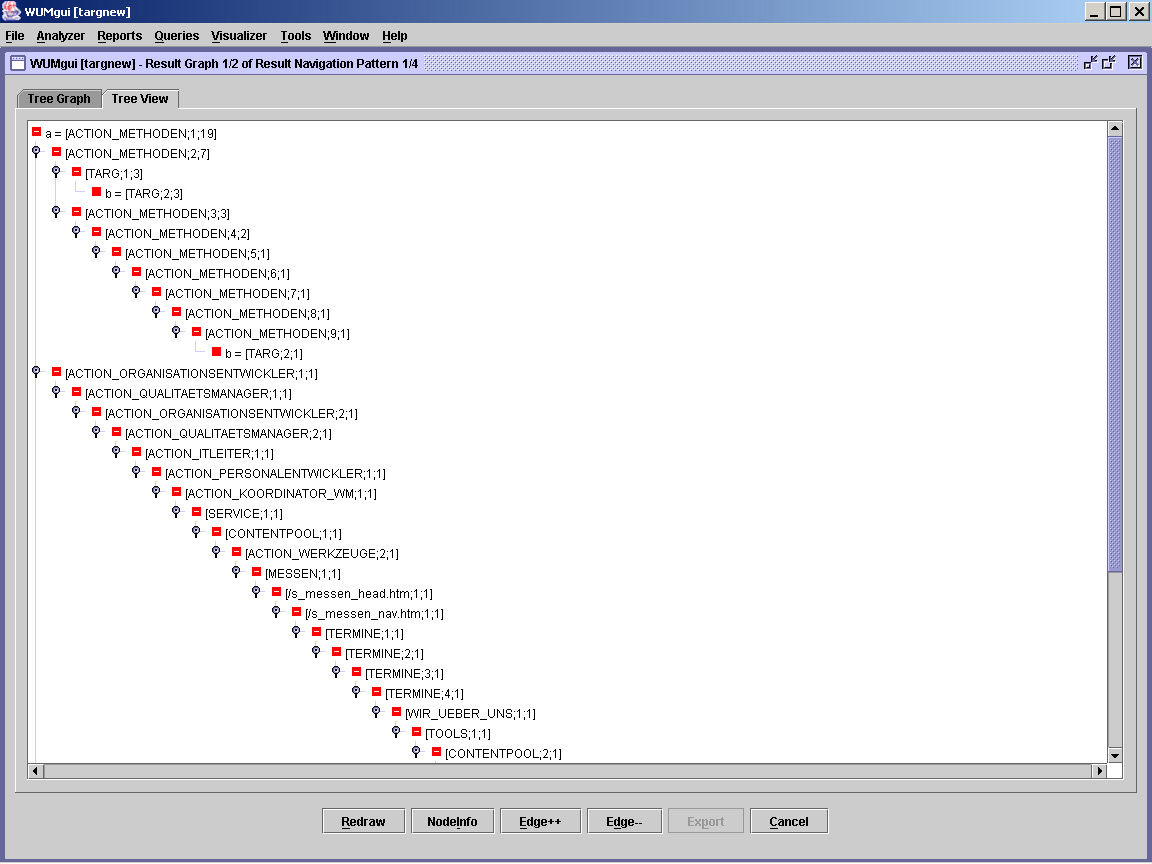
Abb. 6 METHODEN PatternID 1
von 19 Usern erreichten 4 nach Abrufen von 7, bzw. 9 Ergebnisseiten das Ziel. 2 weitere (auf der Abb. nicht sichtbar) erreichen relativ schnell über WERKZEUGE eine Target-Page. der Siebte unternimmt eine wahre Odyssee durch die Seite, bis er zum Ziel gelangt[5]. Das heißt, dass von 7 "Customern" nur 4 über METHODEN zum Ziel gelangten. Dabei muss man berücksichtigen, dass ich mit den Einschränkungen von Support und Konfidenz hier eigentlich nur "erwünschte" Ergebnisse vorliegen haben sollte. FALLSTUDIEN dagegen (18 Patterns) entsprechen weitestgehend den Pfaden von WERKZEUGEN. Damit stehen ACTION_METHODEN in dem Verdacht, die Besucher abzulenken. Dies überprüfe ich, indem ich im where clause die Beschränkung auf TARG_METH auf TARG ausweite. Damit sind auch TARG_WERK und TARG_FALL als Resultat erlaubt. Das Ergebnis ist mit einer Konfidenz von 30% das gleiche. Also senke ich sie auf 20%. Ich erhalte 4 Resultate mit b.url = "TARG_METH". Die gleiche Frage ohne die Einschränkung METH, also:
select t
from node as a b, template a * b as t
where a.url = "ACTION_METHODEN"
and b.url startswith "TARG"
and a.support >= 5
and (b.support / a.support) > 0.2
bringt nun 6 Patterns, bestehend aus 4 TARG_METH und 2 TARG_WERK, wogegen dasselbe Muster an Werkzeugen und Fallstudien (mit Konfidenz 30%) angewandt bei Werkzeugen 6 Patterns hinzufügte, die alle auf TARG_BIT hinausliefen und von ACTION_WERKZEUG aus aufgerufen worden sind, also keinen einzigen Kategorienwechsel. Noch extremer war der Zuwachs bei Fallstudien: aus 7 Patterns wurden 17, alle zusätzlichen waren Bitkom-Artikel. Die einzige Kategorie, die "Abirrungen" in andere Kategorien enthielt, war Methoden.
Sie ergeben also kaum Treffer mit Konfidenz > 0,3 und enthalten bei niedrigerer Konfidenz Abirrungen. Damit stehen sie in dem Verdacht, entweder die Besucher durch ihre Trefferfülle zu verwirren oder schlicht weniger beliebt zu sein als die beiden anderen , wofür schon der niedrige Support der Action Page dieser Kategorie spricht.
Ich gebe jetzt die Beschränkung auf Target Pages auf, erhalte Support und Konfidenz und schließe in b.url Action Pages aus (where b.url !startswith ACTION). Dies bringt bei Werkzeugen genau die 23 Patterns der TARG-Frage, bei METHODEN 7 Patterns mit sechsen davon wie oben und einem, das bei FOLIEN endet. Zuguterletzt überprüfe ich die Konversionseffizienz anderer Action Pages zu TARG_METH:
select t
from node as a b, template a * b as t
wehre a.url != "ACTION_METHODEN"
and a.url !startswith "TARG"
and b.url ="TARG_METH"
and a.support > 5
and (b.support / a.support) > 0.3
also im Prinzip die gleiche Frage nur mit anderem Antecedens. Dies bringt 3 Patterns, eins mehr als a.url = "ACTION_METHODEN". Die Konversionseffizienz anderer Action Pages zu TARG_METH ist also höher als die der dafür eigentlich zuständigen Seite.
Es bleibt ein letzter Entlastungsgrund" für ACTION_METHODEN: es könnte sein, dass g sequences, die mit dieser Seite beginnen, häufig zu einem Folgeaufruf einer anderen Seite führen, die selbst einen hohen Support hat, aber eine schlechte Konversionseffizienz[6]. Dies testen wir mit:
select t
from node as a b c, template a * b * c as t
where a.url = "ACTION_METHODEN"
and b.support > 4
and b.url != "ACTION_METHODEN"
and b.url !startswith "TARG"
and c.url startswith "TARG"
Die Frage führt zu keinem Resultat.
Weitere Action Pages
Hier erweist sich die Möglichkeit des Einsatzes von Wildcards als hilfreich. Die Action Page PERSONALENTWICKLER weist einen Support von 4 auf. Damit käme sie schon per se als Kandidat für ein Redesign in Betracht. Trotzdem schaut man sich die Konversionseffizienz an: die Frage:
select t
from node as a b, template a * b as t
where a.url = "ACTION_PERSONALENTWICKLER"
and b.url startswith "TARG"
bringt immerhin 2 Patterns mit 4 unterschiedlichen Targetpages und einer Konversionseffizienz von jeweils 25%. Der Aggregate Tree zeigt in drei dieser Patterns als unmittelbare Folgeabrufe zwei weitere Rollen und zwei Kontextaufrufe, bevor die Targetpage erreicht ist. Ersetzt man die Wildcard "*" mit [0;3] werden überhaupt keine Patterns mehr gefunden. Damit kann von Konversionseffizienz für ACTION_PERSONALENTWICKLER keine Rede mehr sein.
Interessant ist natürlich ACTION_INDEX, die mit 220 mit Abstand den höchsten Support aufwies. Dies beinhaltet alle einzelnen Wortabfragen, alles, was im Log mit s_index.htm anfängt, weshalb es nicht verwundert, dass der Support so hoch ist. Interessant ist nun die Occurrence, die dadurch, dass jede der unzähligen Trefferseiten im Log nur als ACTION_INDEX auftaucht, ziemlich anwachsen kann. Genau das ist auch der Fall, doch während dies bei den Kategorien zumindest nicht unerwünscht war, ist es das hier schon: 23 Suchwörter, bevor man zum Ziel kommt, ist nicht das, was man unter benutzerfreundlicher Navigation versteht.
select t
from node as a b, template a * b as t
where a.url = "ACTION_INDEX"
and b.url startswith "TARG_"
and (b.support / a.support) >= 0.2
bringt 25 Patterns, fügt man a.occurrence < 7 hinzu, reduziert sie diese Anzahl auf 3. Das ist umso unerwünschter, als bei einer Konversionseffizienz von 30% und a.support > 5 kein Resultat mehr zu erzielen ist, streicht man die Beschränkung der Occurrences, dagegen 19 Patterns mit Occurrences zwischen 11 und 27.
Fazit
Abgesehen von HOME, SUCHE und INDEX waren die einzigen Action Pages mit nennenswertem Support Fallstudien, Methoden und Werkzeuge. Als Problemkinder erwiesen sich die Methoden und der Index. Beim Index ist die Ursache auf Grund der hohen Anzahl der wiederholten Aufrufe naheliegend: die Fülle der Schlüsselwörter. Da für einen Artikel bis zu 10 Schlüsselwörter eingegeben werden können, haben wir im Moment derer 538. Es wäre also naheliegend, die Vergabe auf z.B. 5 zu beschränken und damit eine höhere Konzentration auf das wesentliche zu erzwingen. Bleibt ACTION_METHODEN. Der Befund legt nahe, beweist aber nicht, dass die Kategorie weniger beliebt als die anderen beiden sind. Dafür spricht der niedrige Support der Action Page (der von Fallstudien ist fast doppelt so hoch), es könnte aber auch eine Art von Information Overflow durch die lange Trefferliste als Ursache heranzuziehen sein. Dafür spräche die hohe Zahl von wiederholten Seitenabrufen. Vermutlich ist ersteres der Fall, schon bei der im März 2002 ausgewerteten Umfrage unserer Besucher ergab sich bei Artikeln führende Positionen für Case Studies und v.a. Tools (vgl. http://www.community-of-knowledge.de/beitrag/auswertung-user-feedback-maerz-01-maerz-02/) Letztlich klären ließe sich das aber nur, indem man den Content Pool der beiden anderen Kategorien auf eine vergleichbar hohe Zahl bringt und dann die Analyse noch mal durchführt.
Die Besonderheit von WUM, das hat die Analyse in aller Deutlichkeit gezeigt, liegt in der Aufdeckung nicht erwarteter Navigationsmuster. Die Struktur der drei Kategorien ist nämlich im Prinzip gleich: der Aufruf einer Kategorie führt zu einer sortierten Liste von Ergebnissen, und da erwartet niemand apriori allzu große Unterschiede. Ebenfalls hervorzuheben sind die Möglichkeiten, die durch Einsatz der Wildcards und Beschränkungen von Occurrences gegeben sind. Denn kurze oder lange Navigationspfade können je nach Beschaffenheit eines Portals / eShops erwünscht oder unerwünscht sein, gleiches gilt für die Inanspruchnahme einer bestimmten Navigationshilfe (bei uns z.B. SUCHE: mit Konfidenz = 0.3 und Beschränkung auf 3 dazwischenliegende Seiten nur ein Pattern!)
Damit ist WUM ein hoch flexibler Miner, der mit adäquatem Hintergrundwissen des Analysten eingesetzt erheblich mehr zu leisten vermag als standardisierte Expertentools.
Literatur
[SF99] M. Spiliopoulou and L. Faulstich. Wum: A tool for web utilization analysis. In Proceedings of EDBT Workshop at WebDB\\\\\\"98, LNCS 1590, pages 184--203. Springer Verlag, 1999.
[SP01] M. Spiliopoulou and C. Pohle. Data mining for measuring and improving the success of web sites. Data Mining and Knowledge Discovery, 5:85--14, 2001
[BHS02] B. Berendt, A. Hotho, and G. Stumme. Towards semantic web mining. In International Semantic Web Conference (ISWC02), 2002
Endnoten
[1] Dank an Andreas Schmidt von debian-user-german.
[2] Dank an Riccarda Cassini von techtalk@linuxchix. Eine Version, die Arrays verwendet (und die anderen beiden Scripts findet man hier (1, 2, 3)
[3] Analogien der Syntax zu SQL sind unübersehbar, führen hier aber nicht weiter.
[4] dazu im vim zeilenweise (kommagetrennte Bereiche) mit obiger Regex, nur TARG_WERK statt TARGET substituieren oder (Windows) im Textpad (dem Editor meiner Wahl unter Windows) den jeweiligen Bereich in regexpr.txt markieren.
[5] Bei diesem Pattern denkt man eigentlich sofort an einen durch das Preprocessing geschlüpften Robot. Zwar anonymisiert WUM die Host-Einträge im Log, man kann die Session jedoch aus der Datei WumSessionLog.txt in seiner Mining Base ermitteln und hat dann den Time Stamp. Der ist eindeutig und verhilft einem sofort zu dem dazugehörigen Host + Useragent im Webserver Log. Für fanatische Robotjäger ist auch der Output von awk "$3 >30 {print $0}" WUM.SessionLog.txt" nicht uninteressant. Hier lag aber eindeutig kein Robotbefall vor.
[6] Vgl. [SP01], S. 13
Kommentare
Das Kommentarsystem ist zurzeit deaktiviert.
Verwandte Beiträge
Schlagworte
Dieser Beitrag ist den folgenden Schlagworten zugeordnet