
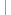
Beiträge
Themengruppen
Recherche
Service
- Was ist Wissensmangement?
- Open Journal of Knowledge Management
- Artikel-Guidelines
- Newsletter
- Kalender
- Wissensmanagement-Anbieter
- Partner
- Mediadaten
Community
Sponsoren

- Robots suchen nach Metadaten, die im Header von html-Dateien stehen. Die bevorzugte Methode im Request ist daher HEAD statt GET (s.o). Sie wird auch von Proxies verwendet, die erfahren wollen, ob eine Seite noch gültig ist.
- Im request-Feld sind entweder nur oder gar keine Bild-Aufrufe zu finden (z.B. bei EmailDigger).
- Das Referrer-Feld ist leer.
- Merkwürdige Dateien wie cmd.exe, system32 oder root.exe im request-Feld.
- Typus des Requests (z.B. ohne gifs)
- Anzahl der aufgerufenen Seiten (für Robots, die in kurzer Zeit so viele Seiten wie möglich indizieren)
- Zeitintervalle zwischen sukzessiven Aufrufen.
Knowledge Discovery in Databases, Teil II - Web Mining
15. Juni 2003 von Gebhard DettmarDie Wissensgenerierung bezüglich der Nutzung von Online-Inhalten gehört im eCommerce zu den vorrangigen Interessensgebieten eines jeden Data Mining-Analysten. Zu diesem Thema haben wir im vorausgehenden 1. Teil dieser Artikelserie besonderen Wert auf die Beschreibung einiger Algorithmen aus dem Bereich des induktiven Lernens gelegt, insbesondere den Apriori-Algorithmus[1], der zur Auffindung von Assoziationsregeln verwendet wird. Das bekannteste und meist verwendete Anwendungsbeispiel, die Warenkorbanalyse, enthält Anforderungen an den Analysten, die im Bereich des Web Mining recht ähnlich anzutreffen sind.
Web Mining
Doch zunächst eine Definition: "Der Begriff Web Mining bezeichnet zunächst die allgemeine Anwendung von Verfahren des Data Mining auf Datenstrukturen des Internet."[2] Dabei ist es üblich, die Verfahren weiter nach Anwendungsbereichen aufzusplitten:
Web Content Mining behandelt die Klassifizierung von Webauftritten nach zuvor festgelegten Kategorien. Die Informationsgewinnung ist hier das Ziel des Erkentnisinteresses, zum Einsatz gelangen vorwiegend Methoden des Text Mining.
Im Web Structure Mining richtet sich das Augenmerk auf die Struktur einer Webseite, i.e. vor allem ihre Verlinkung, mit dem Ziel, die interne Navigation zu verbessern und äußere Verweise, die i.d.R. von inhaltlich verwandten Seiten kommen, zu identifizieren.
Damit ist es, wie auch das Web Content Mining, für Untersuchungen aus dem Bereich Semantic Web [3] interessant, da beide Methoden u.a. für die Erstellung von Ontologien nötig sind. Gleiches gilt für KM-betriebene Unternehmensintranets, die Topic Maps, Knowledge Trees, kurz, aktives Information Retrieval betreiben. So bedienen sich auch ausgewiesene Knowledge Management-Tools wie SER Brainware (neuronale Netze) oder USU Knowledge Miner (Text Mining) Data Mining-Ansätzen, die dem Bereich des maschinellen Lernens entstammen. Eine Sammlung von Tools und Script-Suites im Bereich Knowledge Discovery und Knowledge Management findet man bei Hypknowsys.org. Die dort enthaltene Perl-Script-Suite WUMprep wird mit ihrer Taxonomie-Erstellungs-Funktionalität in der nächsten Folge dieser Serie noch ausführlich behandelt. Der Code, darauf sei gleich hier verwiesen, ist übrigens so gut dokumentiert, dass es auch für Nicht-Programmierer lohnt, einen Blick darauf zu werfen. Es ist an jeder Stelle nachvollziehbar, was das Script gerade macht.
Das Web Usage Mining ist das Verfahren, dem dieser Teil der Artikelserie gewidmet ist. Hier wird das Verhalten der Seitenbenutzer unter Heranziehen der Einträge eines Webserver-Logfiles ausgewertet, um an Hand der dort protokollierten Daten den verschiedensten Fragestellungen nachzugehen. Beispiele sind die Einteilung in Benutzergruppen nach dem Navigationsverhalten und insbesondere die Vorhersage von Seitenaufrufen zur Optimierung des Webauftritts oder der Planung von Marketing-Aktivitäten wie Cross-/Up-Selling. Dazu ist es nötig, sich einen Überblick über die Struktur eines Logfile-Eintrages zu verschaffen.
Das Webserver-Log
Bei Webserver-Logs ist zunächst das Format zu beachten: hier sind v.a. das CFL (Common Logfile Format) und das ECLF (Extended Common Logfile Format) anzutreffen. Untenstehendes Beispiel zeigt das ECLF:
host3111.igd.fhg.de - - [01/Jul/2002:01:47:20 -0600] "GET /cp_rollen.htm HTTP/1.0" 200 29642 "http://www.google.de/search?q=werkzeuge+wissensmanagement&hl=de &lr=&ie=UTF-8&start=10&sa=N" "Mozilla/4.78 [en] (Windows NT 5.0; U)"
Vorab interessant: alle nicht zusammengehörenden Angaben sind durch Leerzeichen getrennt, ein Umstand, den man sich beim Preprocessing der Rohdaten zu Nutze machen wird. Hier nun eine genaue Aufschlüsselung der einzelnen Einträge [4]:
Feldname | Bedeutung |
Host | IP-Adresse des zugreifenden Servers, i.e. des Client-Providers |
Ident | Identifikation (selten vorhanden) |
Authuser | Apache Modul für passwortgeschützte Seiten |
Date | Datum und Uhrzeit des Zugriffs |
Timezone | Abweichung von der Greenwich Mean Time (GMT) in Stunden |
Request | Methode (i.d.R. Get und Post), Dokument, Protokoll (im WWW natürlich http und Versionsnr.) |
Statuscode | 200 = erfolgreich; 404 = Seite nicht gefunden |
bytes | Anzahl der übertragenen bytes |
Referrer | URL der Seite, von der zugegriffen wurde (oben:Google) |
Useragent | verwendeter Browsertyp des Clients; Betriebssystem |
Das heißt für unseren Eintrag:
Die Datenaufbereitung (Data Cleaning)
Worin auch immer die Fragestellung eines Web Mining-Analysten in einem konkreten Fall besteht, sie wird sich immer auf
a) Nutzungsvorgänge und
b) Nutzer
beziehen und er hat nichts anderes als eine Summe sehr ähnlicher Daten wie den oben stehenden Eintrag für die Informationsgewinnung und das zu extrahierende Wissen über Nutzungsvorgänge und Nutzer zur Verfügung.
Das ist zunächst einmal gar nichts. Ohne umfangreiches Preprocessing dieser Daten hat er nur die Summe aller Hits, und diese Zahl ist nicht verwertbar. Tatsächlich stehen in der request-Spalte eines Logfiles nämlich eher selten htm/html als Dateiendung. Weitaus häufiger ist es gif/jpg und wir werden sehen, wieviel von einem 120MB ASCII-File übrig bleibt, wenn man alle gif/jpg/css etc. heraus nimmt, i.e. alle Dateien, die über Nutzerinteressen, Navigations-/Kaufverhalten, kurz: relevante Fragestellungen nichts auszusagen vermögen. Dies ist schnell einzusehen, wenn man bedenkt, dass HTML eine Seitenbeschreibungssprache ist, in der alles, was nicht als Hypertext beschrieben werden kann, über Tags wie img src="images/_h_xcontent.gif" als Datei eingebunden wird. Der Tag besagt: auf dem Webserver gibt es einen Ordner namens images, in dem ein Bild mit dem kruden Namen _h_xcontent.gif liegt, das zusammen mit der html-Datei (=ASCII) an den Client geliefert werden soll, der über die GET-Methode einen Auslieferungsantrag für die Seite cp_rollen.htm gestellt hat. Existiert für die Seite keine Zugriffsbeschränkung, bekommt er sie auch.
Es wird wohl niemand auf die Idee kommen, die c-o-k als bilderlastige Seite zu bezeichnen. Doch ohne Logos oder erläuternde Diagramme kommen auch wir nicht aus. Man muss selbst einmal ein kurzes Filterscript über ein Logfile gelaufen lassen haben, um eine Vorstellung davon zu bekommen, wieviele aller Hits auf Logos und dergleichen entfallen. Dabei sind alle Angaben zu Hits nicht nur uninteressant und unseriös - allein die Angabe der sog. Pageviews ist maßgebend - ein ungefiltertes Logfile behindert auch die Arbeit des Analysten. So würde die Assoziationsregelentdeckung, die im Web Mining nach dem im ersten Teil der Serie beschriebenen Verfahren der Warenkorbanalyse über den Apriori-Algorithmus betrieben wird, eine unüberschaubare Masse von Pseudo-Regeln nach dem Muster a.html -> x.gif erzeugen, von Regeln also, die eigentlich schon in a.html festgeschrieben sind (das Konsequens x.gif wird bereits im Antecedens a.html über das tag img src formuliert), was der Algorithmus aber nicht merken kann, da sie in seiner Datenquelle als getrennte Einträge erscheinen. Nun ist dieses Problem nicht schwer zu lösen - im Gegensatz zu einem weiteren.
Die Angabe von Pageviews impliziert eine vorausgegangene Filterung, also Visits ohne Bilder - leider allerdings, und hier haben wir es mit einem ernsthaften Hindernis zu tun, nicht ohne Robots. [5] Ein einzelner Seitenaufruf der c-o-k erzeugt im Schnitt 4 Log-Einträge, d.h, 3 von 4 Einträge beziehen sich auf Bilder, die in einem unten beschriebenen Verfahren aus dem Logfile eliminiert werden. Doch würden Robots weiterhin irreführende Regeln in der Assoziationsregelentdeckung erzeugen. Deshalb müssen vor Beginn der Datenaufbereitung Robots aus dem Logfile eliminiert werden, und zwar als erster Schritt, da man für die meisten Heuristiken (s.u.) ungefilterte Daten (raw data) benötigt.
Man vs Machine: die "Robot Detection"
Die in der Data Cleaning-Phase mit Abstand schwierigste und insgesamt auch nur näherungsweise zu lösende Aufgabe stellen dem Analysten Web Robots, also kleine Computerprogramme, die die Verzweigungen des WWW durchlaufen, vorrangig um Seiten für Suchmaschinen zu indexieren, Verlinkungen zu überprüfen oder eMail-Adressen einzusammeln [6]. Tan und Kumar [7] unterscheiden zwischen ethischen und nicht ethischen Robots. Ersterer Typus hält sich an die (inoffiziellen) Regeln des Robots Exclusion Standards und sucht beim Eintritt in eine Seite die Datei robots.txt im Verzeichnis des Web Servers auf, in der Verhaltensregeln für Robots festgelegt sind, i.e. erlaubte und nicht erlaubte Seiten. Darüber können sie in der request-Spalte identifiziert und ihre Folgeaufrufe im Zuge des Sessionizing (s.u.) aus dem Log entfernt werden.Weiterhin sollten sie sich im User Agent Feld durch Zusatz-Einträge wie Googlebot zu erkennen geben.
Bei der zweiten Variante wird es schwierig. Alle Verfahren zur Filterung von nicht-ethischen Robotern sind Näherungen, auf die im Rahmen dieser Serie nur ansatzweise eingegangen werden kann. Bestimmte Einträge im Logfile deuten auf nicht-menschliche Clients:
Allerdings ist das Referrer-Feld auch bei allen Einträgen, die von menschlicher Natur herrühren, leer, wenn URL"s in die Adress-Zeile des Browsers getippt, aus Bookmarks/Favoriten heraus oder über den Back-Button und nicht über Hyperlinks angefordert wurden [8], desgleichen beim Reload einer Frameset Seite mitten in einer Session. Tan und Kumar [9] verfolgen daher den Ansatz, insb. "Camouflaging Robots" über ihr Navigationsverhalten zu identifizieren, was auf der Vorannahme beruht, dass dieses sich von dem des Menschen unterscheidet. Hierzu machen sie im wesentlichen drei Charakteristiken aus:
Anschließend wird das Logfile einem Sessionizing unterzogen (s. Abschnitt 5), d.h. über die IP-Adressen-, Time Stamp- und User-Agents-Einträge werden den einzelnen Requests User-ID"s zugewiesen. Man weiß nun, welche Sequenz von Seitenabrufen einer einzelnen Sitzung entstammen, wobei es noch keine Rolle spielt, ob dahinter Robots oder Menschen stehen. Der nächste Schritt besteht darin, den einzelnen Sessions Eigenschaften und Attribute zuzuweisen, die sich nach den oben aufgeführten Merkmalen (Verwendung der HEAD-Methode usw.) richten. Gemäß Charakteristik 2 und 3 sind die durchschnittliche Dauer und ihre Standardabweichung für die Identifizierung nicht ethischer Roboter besonders relevant.
Nun werden die im Log eingetragenen User-Agents in vier Kategorien eingeteilt: 1. bekannte Robots, 2. bekannte Browser, 3. mögliche Robots und 4. mögliche Browser.
All diese Schritte dienen der Definition von Kriterien für die Identifizierung von Robots, aus denen so Klassifizierungs-Algorithmen für deren automatisierte Bestimmung geschrieben werden können. Diese Algorithmen generieren der Aufgabe entsprechend u.a. die vier Typen von User Agents sowie html-Abruf-Mengen in einem vordefinierten Zeitraum. Abschließend müssen noch zwei Klassen-Labels der durchlaufenen Sessions, sc. s.Class=0 für menschliche und s.Class=1 für maschinelle Urheber der Sessions generiert werden [10], was sich nach solcherart Vorarbeit durch einfache Zuweisungen realisieren lässt, wie folgender Auszug verdeutlicht:
6. if Type 1 ∈ AgentTypes or Type 3 ∈ AgentTypes
7. then s.Class = 1
8. else s.Class = 0
Laut Tan und Kumar können damit 90% der nicht-ethischen Robots, deren Navigationsverhalten dem bekannter Robots ähnelt, identifiziert werden. Allerdings stellten sie im Laufe der Untersuchung fest, dass es auch Robots mit Menschen-ähnlichem Verhalten gibt, denen durch oben beschriebene Methodik nicht beizukommen ist. Hier kann nur weitere Forschung Identifikationsmuster erarbeiten.
Datenaufbereitung ohne externe Tools
Die weitere Filterung erfolgt seitens des Analysten i.d.R. über Perl-Scripts [11]. Doch schon mit den Mitteln des Betriebssystems (nicht des Kernels im engeren Sinne) lassen sich nicht nur die Dateien, die in html-Seiten über Tags wie "img src" eingebunden sind, recht leicht entfernen. Auch nach Abschluss der Aufbereitungsphase braucht man sie laufend für die Fragestellungsspezifische Datenextrahierung. Unter Unix verwendet man dazu die Tools sed, grep und awk, unter Windows, oder besser: DOS, das grep-Pendant FIND. Da diese Kommandos immer wieder benötigt werden, sollte man sich von vornherein angewöhnen, sie in sog. Shell-Prozeduren (Unix), bzw. Stapeldateien (DOS, die bekannteste dürfte autoexec.bat sein) zu schreiben. Man muss sie dann nur noch vom Terminal, bzw. der DOS Eingabeaufforderung oder dem Explorer aufrufen, die enthaltenen Befehle werden zeilenweise abgearbeitet. Schon mit FIND kommt man recht weit, die Syntax lautet:
FIND [/V] [/C] [/N] [/I] "string" [[Laufwerk:][Pfad]Dateiname]], mehr dazu mit "find /?".
Die Ausgabe dieses Befehls leitet man via ">" von der Standardausgabe in eine noch nicht existierende Datei um. Bei den Optionen interessieren uns v.a. "/v" (=inverse; unter Linux: grep -v). Sie "grept" nach allen Zeilen, die nicht nachfolgenden regulären Ausdruck enthalten. Die Reinigung von gif erfolgt also durch:
find /v "gif" c:\\..\\..\\logfileXY > ohne_gif
Ein Screenshot verdeutlicht die Arbeitsweise der Prozedur (logfilter.bat), in der die Kommandos der "Stapelverarbeitungsdatei" zeilenweise abgearbeitet werden:
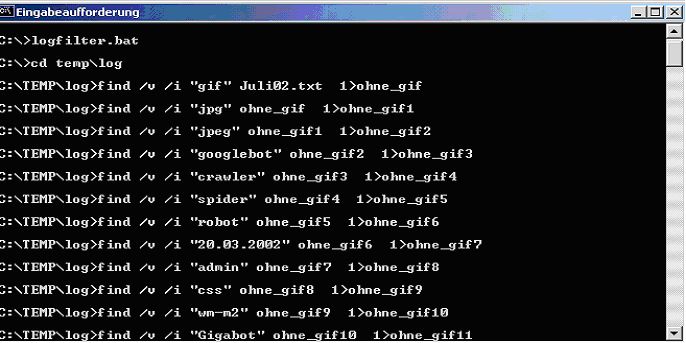
Abbildung 1: Screenshot find
Zu beachten ist, dass ">" bereits existierende Dateien überschreibt und ">>" anhängt. Im Prinzip hätte man hier überschreiben können, doch dann wäre man der Option verlustig gegangen, sich mit anschießendem DIR Befehl anzuschauen, was die einzelnen Ausdrücke an Filterleistung gebracht haben. In obigem Beispiel kam ich von 40MB auf knapp 5. Natürlich ist insb. die Art der Robot Filterung hier absolut "quick and dirty". Eigentlich dürfte man nicht einfach nach "bot" greppen, da möglicherweise nur die Zeile, in der die robots.txt angefordert wird, den String enthält und er in der nun folgenden Session nicht mehr auftaucht. Damit würde man das Sessionizing gründlich verderben. Da aber jeder ethische Robot entweder "bot", "crawler" oder "spider" im Host oder User Agent stehen haben sollte, müssten theoretisch auch die Folgeabrufe einer Robot-generierten Session entfernt werden. In der Praxis ist das nicht der Fall.
Deshalb weise ich darauf hin, dass man das Preprocessing mit einer professionellen Script-Suite wie WUMprep in der festen Reihenfolge: Sessionizing, Robot Detection, Log Filter durchführen und obige Befehle zu ad hoc-Fragestellungen im Verlauf der Auswertung verwenden sollte. Denn es gibt zahlreiche weitere Analyse-Aufgaben, die sich mit vergleichbaren Befehlen durchführen lassen. Beispiele wären:
Wieviele tote Links gibt es auf unsrere Seite? -> find "404"... >tote_links
Wie oft werden die Product Placements unserer Sponsoren aufgerufen -> find "artikel_ID =xy" >sponsor
Wie oft dagegen Artikel vergleichbaren Inhalts, etc.
Hilfreich ist es natürlich, wenn man das an einem bereits vorgefilterten File durchführt. Doch gerade nach Abschluss der Datenaufbereitungsphase, wenn das eigentliche Web Usage Mining, i.e. die Logfileanalyse unter Einsatz entsprechender Tools zum Zuge kommt, werden sich aus deren Analyse-/Abfrageergebnissen permanent ergebnisspezifische Fragestellungen ergeben, die Kommandozeilenbefehle bzw. Shellprozeduren nötig machen.
Wir verwenden für das Web Usage Mining WUM (Web Utilization Miner), ein High End-Tool, das am Lehrstuhl für Wirtschaftsinformatik der HU-Berlin und der Handelshochschule Leipzig von den Data Mining-Spezialisten und Java-Programmierern Bettina Berendt, Karsten Winkler, Myra Spiliopoulou, Steffan Baron, Carsten Pohle und Lukas Faulstich entwickelt wurde, die an ihren Instituten auch eine spannende Lehre unter Einsatz richtungsweisender Methoden anbieten [12]. Das Tool verwendet rechenintensive Algorithmen wie Apriori und die selbstentwickelte, an SQL angelehnte Abfragesprache MINT. Wir haben im ersten Teil dieser Serie die Performance-Probleme von Apriori angesprochen, für MINT gilt dies in gleichem Maße. Es ist daher schon aus Effizienzgründen vollkommen indiskutabel, irgendeine spezifische Fragestellung auf das ungefilterte Logfile anzuwenden. Ich muss daher nochmals betonen: Usertools wie sed, grep und awk sind im gesamten Mining-Prozess unverzichtbare Begleiter und gewährleisten gerade in der Kombination mit Anwendungstools effektives Mining.
Da diese Werkzeuge unter DOS nicht zur Verfügung stehen, muss man sie, z.B. unter Sourceforge, herunterladen.
Nicht nur für die Logfileanalyse nützlich ist besagtes awk. awk ist so mächtig, dass man im Prinzip relationale Datenbanken damit erstellen, verwalten und abfragen könnte. Die Analysefähigkeiten von (nicht immer) kostenlosen Tools wie Analog dagegen übertrifft er bei weitem. sed ist ein nicht interaktiver, zeilenorientierter Editor, der sehr ähnlich wie awk arbeitet, nicht so mächtig, dafür aber schneller ist.
Hier ein Anwendungsbeispiel: Eine übliche Frage von Analysten, die aus dem Bereich des Web Structure Mining (s.o.) stammt, lautet: Welche externen Referrer führen Nutzer auf unsre Seite? awk identifiziert Spalten in einer Zeile durch Leerzeichen, der Referrer wäre in obigem Beispiel also Field 11. Der Befehl lautete dann:
awk -FS = "?" ; {print $ 11} logfile |grep -v "www.c-o-k.de" |sort |uniq >externe_refs
Mit awk drucken wir alle Einträge in Spalte 11, i.e. der Referrer-Spalte nach Stdout, wobei die Search-Strings, die man nicht benötigt, und die die abschließende Filterung mit uniq verderben würden, über die Option -FS = Field Separator separiert werden. Alternative dazu wäre "sed -e s/?/ /g": s steht für substitute, es folgt das zu ersetzendes Zeichen, dann das neue (in diesem Falle Leerzeichen) und g für global, i.e die Adressierung des Befehls, die mit global das gesamte File umfasst. Das Ergebnis kommt an der Bildschirmausgabe jedoch nicht an, da wir es über die Pipe, die Eingabe-/Ausgabeumleitung erst grep übergeben, das mit der Inverse-Option -v die internen Referrer eliminiert, die alle den eigenen Domainnamen enthalten und hier nicht gefragt sind. Dessen Ausgabe wird als Eingabe an sort umgeleitet, das alle Duplikate untereinander auflistet (wer wissen will, wieviel allein von Suchmaschinen kommen, z.B um sich Klarheit darüber zu verschaffen, welche Searchstrings Auskunft über Interessenprofile geben, macht das über grep/find, s. oben), die wiederum über die Eingabe an uniq entfernt werden. Die Ausgabe dieses letzten Befehls wird in die Datei externe_refs umgeleitet, in der nun schön übersichtlich jeder externe Referrer einzeln aufgelistet ist. All das sähe unter DOS genauso aus, mit der Einschränkung, dass sed, awk und uniq nicht zur Verfügung stehen und heruntergeladen werden müssen. [13]
Sessionizing
Das Sessionizing dient der Identifizierung von Navigationspfaden, die ein Nutzer in einer Sitzung durchlaufen hat. Jede weitere Analyse basiert auf der korrekten Zuordnung dieser Pfade zu einem einzelnen Nutzer. Dabei geht es nicht um seine vollständige Identifizierung, wie es bei anmeldungspflichtigen Seiten geschieht, lediglich die Zuordnung Nutzer - Seitenabrufe ist entscheidend.
IP-Adressen, insbesondere unter IPv 4 mit lediglich 32 bit Formatierung [14], werden in aller Regel dynamisch vergeben. Daraus folgt, dass Nutzer mit der Spalte 1 im Logfile mitnichten hinreichend zu identifizieren sind. Zudem sind bei manchen Internetzugängen Proxyserver optional oder zwangsweise vorgeschaltet, die im Logfile als einzelne IP-Adresse erscheinen. Darüberhinaus machen sich vor allem Modem-Benutzer die Funktion des Browser-Caching zu Nutze, durch die Logeinträge verloren gehen, was das Sessionizing unausweichlich bruchstückartig werden lässt.
Diesem Problem begegnet man im Sessionizing durch Heuristiken, die die Rekonstruktion von User-Sessions ermöglichen sollen. Ich übergehe hierbei alle Sonderfälle und Hilfsmittel wie Cookies, Packet Sniffing u.s.w., die alle ihre je eigenen Fußangeln bergen, und konzentriere mich weiterhin auf das pure Logfile als der Quelle von Webdaten schlechthin.
Unterschieden werden zeit- und navigationsorientierte Heuristiken. Erstere legen einen geschätzten Wert der üblichen Verweildauer fest, der von Catledge und Pitkow auf 30 Minuten gerundet wurde [15]. Wenn also die Timestamp-Einträge einer IP-Adresse im Log 75 Minuten betragen, würde man 3 Nutzer rekonstruieren. Dieser Wert stellt jedoch lediglich eine Übereinkunft dar.
Letztere legen als Prämisse der Session-Identifikation fest, dass URLs nicht getippt, sondern über Hyperlinks aufgerufen werden. Dies lässt sich gut an Hand der Artikel der c-o-k nachvollziehen. Um den URL einer Seite über die Tastatur-Eingabe zu erreichen, müsste ein Nutzer die Maus über den Link halten, sich Strings wie /cp_artikel.htm?artikel_id=137 einprägen und in das Adressfeld eingeben. Ein solches Navigationsverhalten kann man in der Tat getrost ausschließen, dennoch gelten für diese Heuristik immer noch zwei der unter Abschnitt 4 genannten Einschränkungen.
Folglich trennt die Heuristik alle Einträge im Request-Feld, die nicht von vorausgegangenen Einträgen ausgegangen sein können, weil dort kein Link vorhanden war.
Der Algorithmus zur zeitorientierten Heuristik verwendet wieder einen Schwellenwert q, der nicht überschritten werden darf. t0 ist dann der Time Stamp des ersten URL-Requests und jeder URL, für dessen Time Stamp t gilt: t - t0 ≤ q, wird dem mit t0 versehenen URL als Folge-Aufruf einer Session zugeordnet. URLs, die innerhalb des Schwellwerts q liegen, bilden zusammen eine Sequenz. Der erste URL mit t > t0 + q wird zum ersten URL der nächsten Session usw.
Der Algorithmus zur navigationsorientierten Heuristik setzt folgende Annahmen voraus: p und q seien zwei aufeinanderfolgende Seitenaufrufe mit Time Stamp tp und tq, p gehöre zu einer Session S. q wird dann als S zugehörig erkannt, wenn ihr Referrer zuvor innerhalb der Session S aufgerufen wurde, oder - falls das Referrer-Feld aus dem Zeichen "-" besteht (Gründe s.o.) -, wenn für eine festgesetzte Ladeverzögerung D (tq - tp) ≤ D ist. Diese Ladeverzögerung wird für Frameset-Reloads benötigt.
Damit ist die Data Cleaning-Phase abgeschlossen. Nach einem unveröffentlichten Forschungsbericht von Daniel Delic, der sich momentan bei Bettina Berendt promoviert, über die Logfileanalyse des Portals MINT, ein Kompetenzzentrum für naturwissenschaftlich-mathematischen und informatischen Unterricht der Freien Universität Berlin, sind nur ca. 25 % der generierten Sessions menschlichen Ursprungs. An unserem bat-gefilterten Logfile (s.o.) generieren Sessionize-Perl-Scripts rund 50% der Sessions gegenüber dem raw-file, so dass sich zumindest vermuten lässt (i.e. bei vergleichbarem Robots-Befall), dass ich rund 25% nicht entdeckt habe. Grundsätzlich kann man wohl davon ausgehen, dass der relative Robot-Anteil eines Webserver-Logs bei steigender Userzahl sinkt, da Robots zwischen stark und wenig besuchten Sites nicht unterscheiden, i.e. der absolute Befall in beiden Fällen gleich sein müsste. Im Fall der c-o-k teste ich gegen, indem ich die von The Web Robots Pages stammende Robot-Datenbank indexers.lst aus WUMprep nach bewährtem Muster auffülle:
Ich nehme ein möglichst großes Log, das ich nach ethischen Bots filtere. Die Treffer füge ich Indexers.lst hinzu mit:
grep "bot" log |gawk "{print "robot-host: ", $1}" |sort |uniq >>indexers.lst.
Detect und RemoveRobots.pl aus WUMprep stützen sich auf diese Datenbank und 2 Heuristiken: robots.txt für ethische und maxViewTime für nicht-ethische Robots - was fehlt, sind leere Referrer-Felder innerhalb einer Session - und identifizieren damit 17% vor und 22% nach Auffüllen von indexers.lst als Robot-generiert. Im Output-File vermag ich nicht-ethische Robots mit bloßem Auge nicht zu erkennnen.
In der nächsten Folge werden wir uns dem eigentlichen Web Usage Mining zuwenden. Dabei wird ein Tool vorgestellt, dass auf seinem Gebiet state-of-the-art ist: der Web Utilization Miner WUM. Mit der begleitenden Unterstüzung von mit WUMprep erzeugten Taxonomien und ad hoc-geschriebenen sed-/awk-Kommandos wird an einigen c-o-k-Logs genauestens vorexerziert, wie die Wissensgenerierung bezüglich der Nutzung von Online-Inhalten vonstatten geht und wie die Verbindung von Web Usage Mining und Semantic Web konkret aussehen könnte.
Endnoten
[1] Grundlegend: Agrawal, R., Imielinski, T., Swami, A., Mining Association rules between sets of items in large databases. In: Proceedings of the ACM SIGMOD Conference on Management of Data, Washington, DC, 1993, S. 207-216.
[2] zit. n. Hippner, Merzenich, Wilde (2002), S. 6.
[3] Semantic Web s. http://www.community-of-knowledge.de/schlagwort/semantisches-web/
[4] vgl. Hippner, Merzenich, Wilde (2002), S. 10.
[5] Den Robot-Anteil in Angaben zu Pageviews zu bestimmen, ist in der Praxis kaum möglich. Er wird zwischen 20%-70% schwanken.
[6] Zu welchen Problemen das führt, brauche ich niemandem zu erklären. Gewöhnen Sie sich an, eMail-Links hexadezimal zu codieren oder als bmp einzubinden. Dies zwingt Spambots zur Kapitulation. Diverse Lösungen - JavaScript, PHP etc - zu diesem Problem gibt"s z.B. bei GulliWebmaster
[7] Die grundlegende Untersuchung zum Thema. Pang-Ning Tan and Vipin Kumar, Discovery of Web Robot Sessions based on their Navigational Patterns, in: Data Mining and Knowledge Discovery, 6 (1) (2002), S. 9-35. Eine ausgezeichnete Untersuchung, die sich vorwiegend auf Tan/Kumar stützt, hat Nicolas Michael im Rahmen eines Web Mining Seminars bei Bettina Berendt vorgestellt.
[8] Für weitere Beispiele s. Bettina Berendts Slides: vasarely.wiwi.hu-berlin.de/lehre/2002w/wmi/Session5/ data_preparation_from_PKDD_tutorial_2002.pdf (last access 22.05.03)
[9] wie Anm. 5, S. 9 ff.
[10] vgl. ebd., Session Labeling Algorithm in Table VII, S. 18.
[11] Vgl. logFilter.pl aus WUMprep von Carsten Pohle unter www.hypknowsys.org (GNU (LGPL))
[12] wovon man sich unter www.wiwi.hu-berlin.de/~berendt überzeugen mag. Siehe auch die WUM-/DIAsDEM- und WUMprep-Entwickler Karsten Winkler und Carsten Pohle.
[13] Z.B. bei Uwin von AT&T findet man auch eine Unix-Emulation für Windows (mit Korn-Shell).
[14] 32 bit sind 4 byte. 1 Byte sind 28 = 256, unter Einbeziehung der Null 255. Eine IP-Adresse besteht also aus 4 Ziffern (= 4Byte) zwischen 0 und 255.
[15] S. Berendt, Mobasher, Spiliopoulou, Wiltshire, Measuring the Accuracy of Sessionizers for Web Usage Analysis, S. 2, www.dia.uniroma3.it/webdb98/papers/12.ps. Vgl. den Gegensatz zum Schwellwert für die Roboter-Identifikation.
Literatur/Links
Hajo Hippner (Hg), Handbuch Web Mining im Marketing : Konzepte, Systeme, Fallstudien, Braunschweig 2002.
Berendt, Mobasher, Spiliopoulou, Wiltshire, Measuring the Accuracy of Sessionizers for Web Usage Analysis, S. 2
Prof. Dr. Bettina Berendt, HS Web Mining, SS03, Institut für Wirtschaftsinformatik der wirtschaftswissenschaftlichen Fakultät der HU-Berlin
Pang-Ning Tan and Vipin Kumar, Discovery of Web Robot Sessions based on their Navigational Patterns, in: Data Mining and Knowledge Discovery, 6 (1) (2002), S. 9-35.
Nicolas Michael, Erkennen von Web-Robotern anhand ihres Navigationsmusters
Kommentare
Das Kommentarsystem ist zurzeit deaktiviert.
Verwandte Beiträge
Schlagworte
Dieser Beitrag ist den folgenden Schlagworten zugeordnet